Теория операционных систем
Формулировка задачи
| Я что-то не вижу пивного ларька. Должно быть, его Успели снести за ночь. Б. Гребенщиков |
Чтобы понять, какие же методики применимы для взаимодействия параллельно
исполняющихся нитей, давайте более четко сформулируем задачу. Для этого
нам также надо ввести некоторое количество терминов. Кроме того, нам придется
высказать ряд соображений, часть которых может показаться читателю банальностями.
Установим, что для каждой из нитей создается иллюзия строго последовательного
исполнения (например, обработчик прерывания может создать для основного
потока программы такую иллюзию, аккуратно сохраняя при вызове и восстанавливая
при завершении все регистры процессора). Если для какой-то из нитей это
условие не всегда соблюдается, мы будем считать ее двумя или большим числом
различных нитей. Если это условие не соблюдается никогда, мы имеем дело
с процессором нефон-неймановской архитектуры.
Общепринятое название для взаимодействия между различными нитями — асинхронное
взаимодействие, в противоположность синхронному
взаимодействию между различными модулями последовательно исполняемой
программы.
Если нить работает только с объектами (под объектом мы, в данном случае,
понимаем не только группу переменных в оперативной памяти или объект в
смысле ООП, но и физические объекты, например управляемые компьютером
внешние устройства), состояние которых не может быть изменено другими
нитями, проблемы взаимодействия, да и самого взаимодействия, как такового,
не существует.
Если нить работает с объектами, состояние которых вообще не подвергается
модификации, например, с кодом или таблицами констант, проблемы также
нет. Проблема возникает тогда и только тогда, когда модификации подвергается
объект, разделяемый несколькими нитями. При этом для возникновения проблемы
достаточно, чтобы только одна нить занималась модификацией, а остальные
нити считывали состояние объекта.
Интервал, в течение которого модификация нарушает целостность разделяемой
структуры данных, и, наоборот, интервал, в течение которого алгоритм нити
полагается на целостность этой структуры, называется критической
секцией. Задача написания корректной многопоточной программы, таким
образом, может решаться двумя способами: либо искоренением критических
секций из всех используемых алгоритмов, либо обеспечением гарантии того,
что никакие две нити никогда одновременно не войдут в критическую секцию,
связанную с одним и тем же разделяемым объектом. Наличие в программе критической
секции с негарантированным исключением и есть ошибка соревнования, которая
рано или поздно сработает.
Полное искоренение критических секций из кода требует глубокой переработки
всех алгоритмов, которые используются для работы с разделяемыми данными.
Результат такой переработки мы видели в примере 5.2: странная, на первый
взгляд, двойная загрузка регистра в настроенной записи PLT в этом примере
обусловлена именно желанием избежать проблем при параллельной настройке
одной и той же записи двумя разными нитями (в качестве упражнения читателю
предлагается разобраться, в каком порядке интерпретатор модифицирует запись,
и как выглядит промежуточный код). У автора нет примеров, демонстрирующих
невозможность такой переработки в обшем случае, но очевидно, что даже
к крайне простым алгоритмам она совершенно не применима на практике.
Второй путь — предоставление гарантий взаимоисключения
(mutual exclusion) — также непрост, но, в отличие от первого, практически
реализуем и широко применяется.
Примечание
Важно подчеркнуть, что сокращение времени, которое каждая из нитей проводит
в критических секциях, хотя и полезно, со многих точек зрения, в частности
с точки зрения улучшения масштабируемости алгоритма, само по себе оно
проблемы решить не может. Без гарантии взаимоисключения, сокращение критического
времени лишь понижает вероятность срабатывания ошибки соревнования (и,
в частности, затрудняет поиск такой ошибки при тестировании), но не исправляет
эту ошибку.
Группа операций модификации разделяемой структуры данных, которая происходит атомарно (неделимо), не прерываясь никакими другими операциями с той же структурой данных, называется транзакцией. В разд.
Примитивы взаимоисключения
В классической работе Г. М. Дейтела [Дейтел 1987] предлагается несколько последовательных усовершенствований механизма взаимоисключений, основанного на флаговых переменных, и как завершающий этап этого анализа приводится алгоритм взаимоисключений Деккера (пример 7.2).
Пример 7.2. Алгоритм Деккера (цит. по [Дейтел 1987])
program АлгоритмДеккера;
var
избранныйпроцесс: (первый, второй); п!хочетвойти, п2хочетвойти: Boolean;
procedure процессодин;
begin
while true do begin
п1хочетвойти := True;
while п2хочетвойти do
if избранныйпроцесс=второй then
begin
п1хочетвойти := False;
while избранныйпроцесс=второй do;
п!хочетвойти := True;
end
критическийучасток1;
избранныйпроцесс := второй;
п!хочетвойти := False;
...
end
end
procedure процессдва;
begin
while true do
begin
п2хочетвойти := True;
while п1хочетвойти do
if избранныйпроцесс=первый then
begin
п2хочетвойти := False;
while избранныйпроцесс=первый do;
п2хочетвойти := True;
end
критическийучасток2 ;
избранныйпроцесс := первый;
п2хочетвойти := False;
...
end
end D
begin
п1хочетвойти := False;
п2хочетвойти := False;
избранныйпроцесс := первый;
parbegin процессодин;
процессдва;
parend
end.
Недостатки этого решения очевидны. Первый из них — для доступа к одной
и той же критической секции из третьей нити мы должны значительно сложнить
код обеих нитей.
Нa практике, для решения проблемы работы с флаговыми и другими ска-ярными
переменными в многопроцессорных конфигурациях большинство овременных процессоров
предоставляют аппаратные примитивы взаимоисключения:
средства, позволяющие процессору монопольно захватить шину : выполнить
несколько операций над памятью. Реализации этих примитивов различны у
разных процессоров. Например, у х86 это специальный код операции, префикс
захвата шины, который сам по себе не совершает никаких действий, но зато
исполняет следующую за ним операцию в монопольном режиме.
Благодаря этому мы можем одновременно получить старое значение флаговой
переменной и установить новое командой xchg (eXCHanGe,
обменять — операнды обмениваются значениями между собой — пример 7.3)-
Если память модифицируется только одним процессором, исполняющим программу,
префикс блокировки шины не нужен — зато, если процессоров (или других
задатчиков шины) в системе несколько, префикс гарантирует взаимоисключение
и для модификаций флага с их стороны.
Пример 7.3. Реализация примитива testandset через блокировку шины
.globl flag
; 0 = False, I = True
flag: .db 0
proc process1
tryagain:
move eax, 1
lock xchg eax, flag
tst eax
bnz tryagain
критическая секция
; в данном случае о взаимоисключении можно не заботиться
xor eax, eax
move flag, eax
ret
endp
Другие процессоры, например VAX, предоставляют отдельные команды, исполняющиеся
в режиме монопольного захвата шины. В частности, Именно так этот процессор
исполняет команды вставки в очередь и исключения из нее.
Имея возможность произвести атомарно исполняющуюся операцию над скалярной
переменной, мы можем реализовать более сложные схемы взаимоисключения,
используя эту переменную в качестве флаговой, при помощи относительно
простого кода (пример 7.4). В отличие от алгоритма Деккера этот код легко
распространяется на случай более чем двух нитей.
Пример 7.4. Реализация взаимоисключения при помощи атомарной операции testandset (ЦИТ. ПО [Дейтел 1987])
progam npimeptestandset
var активный: Boolean;
procedure процессодин;
var первомувходитьнельзя: Boolean;
begin
while true do
begin
первомувходитьнельзя := True;
while первомувходитьнельзя do
testandset(первомувходитьнельзя, активный);
критический участокодин;
активный := False;
....
end
end;
procedure процессдва;
var второмувходитьнельзя: Boolean; begin
while true do
begin
второмувходитьнельзя := True;
while второмувходитьнельзя do
testandset(второмувходитьнельзя, активный);
критический участокдва;
активный := False;
.....
end
end;
В том случае, если одной из нитей является обработчик прерывания, можно воспользоваться сервисом, который предоставляют все современные процессоры: запретить прерывания на время нахождения основной нити программы в критической секции. Впрочем, указанным способом необходимо пользоваться с осторожностью — это приводит к увеличению времени обработки прерывания, что не всегда допустимо, особенно в задачах реального времени.
Мертвые и живые блокировки
| Потом ударили морозы. Замерзло все, лиса ушла в кредит. Медведь же вмерз в дупло И до сих пор глядит. Б. Гребенщиков. |
Решив проблему взаимоисключения для одиночных разделяемых ресурсов,
мы еще не можем расслабляться. Дело в том, что если мы используем любые
механизмы взаимоисключения для доступа к нескольким различным ресурсам,
может возникнуть специфическая проблема, называемая мертвой
блокировкой (dead lock).
Рассмотрим две нити, каждая из которых работает с двумя различными ресурсами
одновременно. Например, одна нить копирует данные со стриммера на кассету
Exabyte, а другая — в обратном направлении. Доступ к стриммеру контролируется
флаговой переменной flag1, а к кассете —
flag2 (вместо флаговых переменных могут использоваться и более
сложные средства взаимоисключения).
Первая нить сначала устанавливает flag1, затем
fiag2, вторая поступает наоборот. Поэтому, если
вторая нить получит управление и защелкнет flag2
в промежутке между соответствующими операциями первой нити, то мы получим
мертвую блокировку (рис. 7.1) — первая нить никогда не освободит flag1,
потому что стоит в очереди у переменной flag2,
занятой второй нитью, которая стоит в очереди у flagi, занятой первой.

Рис. 7.1. Мертвая блокировка
Все остальные нити, пытающиеся получить доступ к стриммеру или кассете,
также будут становиться в соответствующие очереди и ждать, пока администратор
не снимет одну из "защелкнувшихся" задач.
Цикл взаимного ожидания может состоять и из большего количества нитей
Возможна также мертвая блокировка с участием только одной нити и одного
ресурса: для этого достаточно попытаться захватить одну и ту же флаговую
переменную два раза. Критерием блокировки является образование замкнутого
цикла в графе ожидающих друг друга задач.
Эта проблема может быть решена несколькими способами. Часто применяемое
решение, обладающее, впрочем, серьезными недостатками — это отправка сообщения
программе о том, что попытка установить примитив взаимоисключения приведет
к мертвой блокировке. Это решение опасно во-первых, тем, что сильно усложняет
кодирование: теперь мы вынуждены принимать во внимание не только возможность
захвата примитива другой нитью, но и более сложные ситуации. Во-вторых,
получив ошибку установки флага, программист испытывает сильный соблазн
сделать именно то, чего делать в данном случае нельзя: повторить попытку
захвата ресурса.
Рассмотрим ситуацию, когда две нити пытаются захватить необходимые им
ресурсы, получают сообщение о возможности мертвой блокировки, и тут же
повторяют попытку захвата того же ресурса. Поскольку освобождения ресурсов
не происходит, взаимозависимость между этими нитями не устраняется, и
повторный захват также приводит к сообщению о возможности мертвой блокировки.
Если нити будут циклически повторять попытки захвата, мы получим состояние,
которое называется живой блокировкой (livelock) (рис.
7.2). Это состояние реже рассматривается в учебниках, но теоретически
оно ничуть не лучше мертвой блокировки. Практически же оно гораздо хуже
— если нити, зацепившиеся намертво, тихо висят и причиняют вред только
тем нитям, которым могли бы понадобиться занятые ими ресурсы, то нити,
зацепившиеся заживо, непродуктивно расходуют время центрального процессора.

Рис. 7.2. Живая блокировка
Как живая, так и мертвая блокировки возможны и в ситуации, когда ресурс только один, но примитив взаимоисключения не атомарен, т. е. операция захвата выполняется в несколько этапов.
Живая блокировка при арбитраже шины
Рассмотрим процесс арбитража шины: два устройства соревнуются за доступ
к среде передачи. Устройство начинает передачу и при этом сравнивает передаваемый
сигнал с принимаемым из шины. Возникновение расхождений между этими сигналами
интерпретируется как коллизия (collision) — предполагается, что расхождения
обусловлены работой другого передатчика. Обнаружив коллизию, устройство
прекращает передачу. Сигнал распространяется по шине с конечной скоростью,
поэтому прекратить передачу будут вынуждены оба устройства (в разд. Устройства
графического выхода мы увидим пример того, как в низкоскоростных локальных
шинах это ограничение можно обойти). Таким образом, оба устройства не
могут начать передачу сразу же после того, как в шине "установится
тишина": это приведет к живой блокировке. Схема разрешения коллизий
CSMA/CD (Carrier Sence Multiple Access/Collision Detection, множественный
доступ с прослушиванием несущей и обнаружением коллизий), используемая
в протоколах локальных сетей семейства Ethernet, требует от устройства,
обнаружившего коллизию, ожидания в течение случайного интервала времени.
Единственно правильная реакция на получение сообщения о мертвой блокировке
— это освободить все занятые нитью ресурсы и подождать в течение случайного
промежутка времени. Таким образом, поиск возможных блокировок сильно усложняет
и логику работы самих примитивов взаимоисключения (нужно поддерживать
граф, описывающий, кто кого ждет), и код, использующий эти примитивы.
Простейшее альтернативное решение — разрешить каждой нити в каждый момент
времени держать захваченным только один объект — прост и решает проблему
в корне, но часто оказывается неприемлемым. Больше подходит соглашение
о том, что захваты ресурсов должны всегда происходить в определенном порядке.
Этот порядок может быть любым, важно только, чтобы он всегда соблюдался.
Еще один вариант решения состоит в предоставлении возможности объединять
примитивы и/или операции над ними в группы. При этом программа может выполнить
операцию захвата флагов fiag1 и fiag2
единой командой, во время исполнения которой никакая другая программа
не может получить доступ к этим переменным. Групповая операция выполняется
как транзакция, т. е. либо происходит вся целиком, либо не происходит
вообще. Если хотя бы одна из операций группы приводит к ожиданию, групповой
примитив снимает все флаги, которые успел поставить до этого.
Ожидание с освобождением ресурсов, впрочем, порождает ряд более специфических
проблем. Рассмотрим одну из них: нити А нужны ресурсы X и Y, которые она
разделяет, соответственно, с нитями В и С. Если нить А захватывает ресурсы
в соответствии с предложенным протоколом (освобождая их при неудачной
попытке захвата), возможен такой сценарий исполнения нитей В и С, при
котором нить А не получит доступа к ресурсам никогда. Напротив, захват
ресурсов по мере их освобождения другими нитями может (если В и С сцеплены
по каким-то другим ресурсам) привести к мертвой блокировке. Общего решения
задачи разрешения блокировок и родственных им ситуаций при взаимоисключении
доступа ко многим ресурсам на сегодня не предложено.
Описанное выше явление иногда называют "проблемой
голодного философа". История этого колоритного названия восходит
к модели, которую использовал для демонстрации описанного этого феномена.
Некоторое количество (у Э. Дейкстры — пять) философов сидят вокруг стола,
на котором стоит блюдо спагетти (вместо спагетти можно взять, например,
блины). Спагетти едят двумя вилками. В нашем случае, количество вилок
равно количеству философов, так что соседи за столом разделяют вилку (гигиенический
аспект проблемы мы опускаем).
Каждый философ некоторый (переменный) промежуток времени размышляет, затем
пытается взять лежащие рядом с ним вилки (рис. 7.3). Если ему это удается,
он принимается за еду. Ест он также переменный промежуток времени, после
этого откладывает вилки и вновь погружается в размышления. Проблемы возникают,
когда философ не может взять одну из вилок.

Рис. 7.3. Обедающие философы
Возможны несколько вариантов разрешения происходящих при этом коллизий. Если, например, каждый из философов всегда берет ту вилку, которая свободна, и не отпускает ее, пока не насытится, мы можем получить (хотя и не обязательно получим) классическую мертвую блокировку, в которую будут включены все философы, сидящие вокруг стола (рис. 7.4). Вариант, при котором философ сначала всегда дожидается правой вилки, и лишь взяв ее, начинает дожидаться левой, только повысит вероятность образования цикла.
Рис. 7.4. Мертвая блокировка в исполнении пяти философов
Цикл можно разомкнуть, пронумеровав вилки и потребовав, чтобы каждый
философ брат сначала вилку с меньшим номером, и только потом — с большим.
Если вилки пронумерованы по часовой стрелке, для всех философов, кроме
одного, это требование совпадает с высказанным в предыдущем абзаце — сначала
брать правую вилку, и лишь потом дожидаться левой. Однако для того, кто
попал между пятой и первой вилками, это правило обращается — он должен
сначала дождаться левой вилки, и только потом правую. Легко продемонстрировать,
что этот философ в среднем будет своих вилок дольше, чем остальные четверо.
Если же философ берет вилки тогда и только тогда, когда они доступны обе
одновременно, это может привести к проблеме голодного философа-согласовав
свои действия, соседи бедняги могут неограниченно долгое время оставлять
его голодным (рис. 7.5).

Рис. 7.5. Голодный философ
Примитивы синхронизации
| Я слышу крик в темноте Наверное, это сигнал. В. Бутусов |
Посмотрев на примеры 7.2 и 7.4, внимательный читатель
должен отметить, что используемая конструкция подозрительно похожа на
работу с внешними устройствами в режиме опроса. Действительно, опрос флаговой
переменном в цикле хотя и обеспечивает гарантию взаимоисключения, но обладает
всеми недостатками, которые мы указывали для опроса внешнего устройства.
g случае исполнения параллельных нитей на одном процессоре, данный метод
имеет еще один недостаток: пока одна из нитей занимается опросом, никакая
другая нить не может исполняться, потому что процессор загружен непродуктивной
работой.
Легко видеть, что в данном случае использование прерываний или какого-то
их аналога проблемы не решит: в лучшем случае, "прерывание"
будет вызываться не в той нити, в которой нужно, сводя задачу взаимоисключения
к предыдущей, только с уже новой флаговой переменной, а в худшем — приведет
к возникновению еще одной нити. Задача взаимодействия между асинхронными
нитями, таким образом, сводится к требованию того, чтобы нити в какие-то
моменты переставали быть асинхронными, синхронизовались.
Если у нас уже есть примитив взаимного исключения, мы можем решить задачу
синхронизации, предоставив еще один примитив, который позволяет активному
процессу остановиться, ожидая, пока флаговая переменная не примет "правильное"
значение, и продолжить исполнение после этого. При обработке прерываний
роль такого примитива может исполнять команда остановки процессора: у
всех современных процессоров прерывание останавливает "исполнение"
этой команды, а возврат из обработчика передает управление на следующую
команду, таким образом выводя процессор из спящего состояния. В многопроцессорной
конфигурации можно ввести средство, при помощи которого один процессор
может вызывать прерывание другого — и тогда каждый из процессоров системы
сможет ожидать другого, переходя в режим сна. При реализации же многопоточностп
на одном процессоре (см. разд. Вытесняющая
многозадачность) примитив засыпания (блокировки) нити должен предоставляться
модулем, ответственным за переключение потоков.
Впрочем, если операции над флагом, засыпание потока и его пробуждение
реализованы разными примитивами, мы рискуем получить новую проблему (пример
7.5). Она состоит в том, что если пробуждающий сигнал поступит в промежутке
между операторами testandset и
pause, мы его не получим. В результате операция pause приведет
к засыпанию нашей нити навсегда.
Пример 7.5. Ошибка потерянного пробуждения (lost wake-up bug)
program пауза
var flag: Boolean;
procedure процесс1
var myflag: Boolean
while True do
begin
myflag := True;
testandset(myflag, flag);
if myflag then
(* Обратите внимание, что проверка флага *
* и засыпание — это разные операторы! *)
pause;
критическаясекция();
flag := False;
end
end;
Одно из решений состоит в усложнении примитива pause:
он должен засыпать, если и только если сигнал еще не приходил. Усложнение
получается значительное: мало того, что перед засыпанием надо проверять
нетривиальное условие, необходимо еще предусмотреть какой-то способ сброса
этого условия, если мы предполагаем многократное использование нашего
примитива.
Если писать на ассемблере или родственных ему языках, можно пойти и более
изощренным путем (пример 7.6). Подмена адреса возврата в обработчике прерывания
гарантирует нам, что если прерывание по установке флага произойдет в промежутке
между метками label и ok,
мы перейдем на метку label и, вместо того, чтобы
заснуть навеки, благополучно проверим флаг и войдем в критическую секцию.
Пример 7.6. Обход ошибки потерянного пробуждения
.globl flag
flag: db 0
jmpbuf: dw 0
proc flag_interrupt
push eax
tst jmpbuf
bz setflagonly
; подменяем адрес возврата
move eax, jmpbuf
move sp[RETURN_ADDRESS_OFFSET] , eax setflagonly
move eax, 1
move flag, eax
pop eax
iret endp
proc process!
inove eax, setjmp
move jmpbuf, eax setjmp:
move eax, 1
lock xchg eax, flag
tst eax
bz ok
halt
ok
xor eax, eax move jmpbuf, eax
критическая секция
xor eax, eax move flag, eax
endp
Более элегантный и приемлемый для языков высокого уровня
путь решения этой проблемы состоит в том, чтобы объединить в атомарную
операцию проверку флага и засыпание. Нас с читателем можно поздравить
с изобретением двоичного семафора Дейкстры.
Семафоры
| Но когда ты проспишься, скрой спой испуг, Это был не призрак, эти был только звук Это тронулся поезд, на который ты не попадешь. Б. Гребенщиков |
Семафор Дейкстры представляет
собой целочисленную переменную, с которой ассоциирована очередь ожидающих
нитей. Пытаясь пройти через сема-Фор, нить пытается вычесть из значения
переменной 1. Если значение переменной больше или равно 1, нить проходит
сквозь семафор успешно (семафор открыт). Если переменная равна нулю (семафор
закрыт), нить останавливается и ставится в очередь.
Закрытие семафора соответствует захвату объекта или ресурса, доступ к
кото-Рому контролируется этим семафором. Если объект захвачен, остальные
нити вынуждены ждать его освобождения. Закончив работу с объектом (выйдя
из критической секции), нить увеличивает значение семафора на единицу,
открывая его. При этом первая из стоявших в очереди нитей активизируется
и вычитает из значения семафора единицу, снова закрывая семафор. Если
же очередь была пуста, то ничего не происходит, просто семафор остается
открытым. Тогда первая нить, подошедшая к семафору, успешно проГцет через
него. Это действительно похоже на работу железнодорожного семафо. ра,
контролирующего движение поездов по одноколейной ветке (рис. 7.6)

Рис. 7.6. Железнодорожный семафор
Наиболее простым случаем семафора является двоичный
семафор. Начальное значение флаговой переменной такого семафора
равно 1, и вообще она может принимать только значения 1 и 0. Двоичный
семафор соответствует случаю, когда с разделяемым ресурсом в каждый момент
времени может работать только одна нить.
Семафоры общего вида могут принимать любые
неотрицательные значения. В современной литературе такие семафоры называют
семафорами-счетчиками (counting semaphore).
Это соответствует случаю, когда несколько нитей могут работать с объектом
одновременно, или когда объект состоит из нескольких независимых, но равноценных
частей — например, несколько одинаковых принтеров. При работе с такими
семафорами часто разрешают процессам вычитать и добавлять к флаговой переменной
значения, большие единицы. Это соответствует захвату/освобождению нескольких
частей ресурса.
Многие системы предоставляют также сервисы, позволяющие просмотреть состояние
семафора без его изменения и произвести "неблокируюшуюся" форму
захвата, которая возвращает ошибку в ситуации, когда нормальный захват
семафора привел бы к блокировке. Теоретики не очень любят такие примитивы,
но при разработке сложных сценариев взаимодействия с участием многих семафоров
они бывают полезны.
Во многих современных книгах и операционных системах семафорами называются
только семафоры общего вида, двоичные же семафоры носят более краткое
и выразительное имя мутекс (mutex — от MUTnal
EXclusion, взаимное исключение). Проследить генезис этого названия автору
не удалось, но можно с уверенностью сказать, что оно вошло в широкое употребление
не ранее конца 80-х. Так, в разрабатывавшейся в середине 80-х годов OS/2
1.0, двоичные семафоры еще называются семафорами, а в Win32, разработка
которой происходила в начале 90-х, уже появляется название mutex. Операции
над мутексом называются захватом (acquire)
(соответствует входу в критическую секцию) и освобождением
(release) (соответствует выходу из нее).
Многие ОС предоставляют для синхронизации семафоры Дейкстры или похожие
на них механизмы.
Флаги событий в RSX-11 и VMS
Так, например, в системах RSX-11 и VMS основным средством синхронизации
являются флаги событий (event flags). Процессы и система могут очищать
(clear) или взводить (set) эти флаги. Флаги делятся на локальные и глобальные.
Локальные флаги используются для взаимодействия между процессом и ядром
системы, глобальные — между процессами. Процесс может остановиться, ожидая
установки определенного флага, поэтому флаги во многих ситуациях можно
использовать вместо двоичных семафоров. Кроме того, процесс может связать
с флагом события процедуру-обработчик AST (Asynchronous System Trap —
асинхронно [вызываемый] системный обработчик).
AST во многом напоминают сигналы или аппаратные прерывания. В частности,
флаги событий используются для синхронизации пользовательской программы
с асинхронным исполнением запросов на ввод-вывод. Исполняя запрос, программа
задает локальный флаг события. Затем она может остановиться, ожидая этого
флага, который будет взведен после исполнения запроса. При этом мы получаем
псевдосинхронный ввод-вывод, напоминающий синхронные операции чтения/записи
в UNIX и MS DOS. Но программа может и не останавливаться! При этом запрос
будет исполняться параллельно с исполнением самой программы, и она будет
оповещена о завершении операции соответствующей процедурой AST.
Асинхронный ввод-вывод часто жизненно необходим в программах реального времени, но бывает полезен и в других случаях.
Семафоры и прерывания
Большинство современных ОС предоставляют сервисы, позволяющие без вреда
для остальной системы приостановить и возобновить исполнение пользовательской
нити. Однако мало какая ОС предоставляет такой же сервис для обработчиков
прерываний. Поэтому если ОС и разрешает использование примитивов синхронизации
из прерываний, то всегда с условием, что такое использование не может
приводить к блокировке обработчика.
Например, если для синхронизации используется мутекс, обработчик прерывания
не может его устанавливать, а может только снимать. Это требование накладывает
определенные ограничения на стиль использования семафоров. Если при синхронизации
равноправных нитей каждая из них устанавливает семафор в начале критической
секции и снимает его в конце, используя его и для взаимоисключения, и
для синхронизации, то при взаимодействии нити с обработчиком прерывания
для реализации взаимоисключения приходится использовать запрет прерываний,
а мутекс — только для синхронизации.
Стандартная техника использования мутекса в обработчике прерывания состоит
в следующем (порядок операций важен!): процесс захватывает мутекс, инициирует
операцию на устройстве, которая должна завершиться прерыванием, и захватывает
мутекс еще раз. Если к этому моменту прерывание уже произошло, мутекс
будет свободен и процесс ничего не будет ждать. Если же прерывания еще
не происходило, процесс заснет, ожидая его. Обработчик же прерывания только
снимает мутекс.
Захват участков файлов
Семафоры удобны при синхронизации доступа к единому
ресурсу, такому как принтер или неделимая структура данных. Если же нам
нужна синхронизация доступа к ресурсу, имеющему внутреннюю структуру,
например к файлу с базой данных, лучше использовать другие методы.
Если говорить именно о файле, оказывается удобным блокировать доступ к
участкам файла. При этом целесообразно ввести два типа захватов: для чтения
и для записи. Захват для чтения разрешает
другим нитям читать из заблокированного участка и даже ставить туда такую
же блокировку, но запрещает писать в этот участок и, тем более, блокировать
его для записи. Этим достигается уверенность в том, что структуры данных,
считываемые из захваченного участка, никем не модифицируются, поэтому
гарантирована их целостность и непротиворечивость.
В свою очередь, захват для записи запрещает
всем, кроме установившей его нити, любой доступ к заблокированному участку
файла. Это означает, что данный участок файла сейчас будет модифицироваться,
и целостность данных в нем не гарантирована.
Блокировка участков файла в Unix
Захват участков файла в качестве средства синхронизации был известен еще
с 60-х годов, но в том виде, который описан в стандартах ANSI и POSIX,
он был реализован в ОС UNIX в начале 70-х.
В UNIX возможны два режима захвата: допустимая (advisory) и обязательная
(mandatory). Как та, так и другая блокировка может быть блокировкой чтения
либо записи. Допустимая блокировка является "блокировкой для честных":
она не оказывает влияния на подсистему ввода-вывода, поэтому программа,
не проверяющая блокировок или игнорирующая их, сможет писать или читать
из заблокированного участка без проблем. Обязательная блокировка требует
больших накладных расходов, но запрещает физический доступ к файлу: чтение
или запись, в зависимости от типа блокировки.
При работе с разделяемыми структурами данных в ОЗУ было бы удобно иметь
аналогичные средства, но их реализация ведет к большим накладным расходам,
даже на системах с виртуальной памятью, поэтому ни одна из известных автору
систем таких средств не имеет. Библиотека POSIX threads предоставляет
своеобразную форму мутекса, read/write lock, который, как и описанные
файловые примитивы, может быть многократно захвачен для чтения и лишь
однократно — для записи. Однако мы должны заводить такой примитив для
каждой единицы разделяемого ресурса и не можем одним вызовом захватить
сразу много подобных единиц.
Впрочем, в современных версиях системы UNIX есть возможность отображать
файл в виртуальную память. Используя при этом допустимую блокировку участков
файла, программы могут синхронизироовать доступ к нему (обязательная блокировка
делает невозможным отображение в память).
Мониторы и серверы транзакций
Захват участков файла теоретически позволяет реализовать любую требуемую структуру взаимоисключения для процессов, работающих с этим файлом. Однако, практически, при работе с файлом большого количества нитей (например, многопользовательской системы управления базами данных), различные нити часто оказываются вынуждены ждать друг друга, что приводит к резкому увеличению времени реакции системы. С этим явлением хорошо знакомы разработчики и пользователи файловых СУБД, таких, как FoxPro или dBase IV.В случае СУБД решение состоит в создании сервера БД, или сервера транзакций, который вместо примитивов захвата участков файлов или таблиц предоставляет пользователям понятие транзакции.
Если пользовательская сессия объявила начало транзакции, изменения, которые она вносит в таблицы, непосредственно в таблицах не отражаются, и другие сессии, которые обращаются к вовлеченным в транзакцию данным, получают их исходные значения. Завершив модификацию, пользовательская сессия объявляет завершение транзакции. Транзакция может завершиться как выполнением (commit), так и откатом (rollback).
В случае отката измененные данные просто игнорируются. В случае же выполнения сервер вносит изменения в таблицы, однако во время изменений он все равно предоставляет другим нитям данные в том состоянии, в котором они были до начала транзакции. Такой подход увеличивает потребности в оперативной и дисковой памяти (все данные, изменяемые в ходе транзакции, должны храниться минимум дважды: в измененном и в исходном видах), но обеспечивает резкое сокращение времени реакции и определенное упрощение кодирования: программист теперь не должен явно перечислять все данные, которые ему надо заблокировать в ходе транзакции. Кроме того, Двойное хранение данных позволяет восстановить либо результат транзакции, либо состояние данных до ее начала, после сбоя системы.
Современные серверы СУБД представляют собой сложные программные Комплексы, которые, кроме собственно "развязки" транзакций предоставляют сложные сервисы оптимизации запросов, индексации и кэширования Данных. Да и точное описание понятия транзакции в современных языках запросов к реляционным СУБД (SQL, RPG и др.) несколько сложнее при-Веденного выше. Однако детальное обсуждение этого вопроса увело бы нас Далеко в сторону от темы книги. Читателю, интересующемуся этой темой, Можно порекомендовать книги [Дейт 1999, Бобровски 1998].
Аналогичный серверам транзакций подход нередко используется и в более простых случаях межпроцессного взаимодействия. С разделяемым ресурсом ассоциируется специальная нить, называемая монитором ресурса. Остальны нити не могут обращаться к ресурсу напрямую и взаимодействуют только с монитором. Монитор может предоставлять нитям-клиентам непротиворечивые состояния контролируемого им ресурса (необязательно совпадающие с текущим состоянием ресурса) и устанавливать очередность запросов на модификацию.
Даже при довольно простой стратегии управления ресурсом, монитор полезен тем, что скрывает (инкапсулирует) структуру и особенности реализации разделяемого ресурса от клиентских нитей. Типичный пример мониторного процесса — драйвер внешнего устройства в многозадачных ОС.
Гармонически взаимодействующие последовательные потоки
В разд.
Примеры реализаций средств гармонического взаимодействия
Программные каналы Unix
Одним из наиболее типичных средств такого рода является труба (pipe) или
программный канал — основное средство взаимодействия между процессами
в ОС семейства Unix. В русскоязычной литературе трубы иногда ошибочно
называют конвейерами. В действительности, конвейер — это группа процессов,
последовательно соединенных друг с другом однонаправленными трубами.
Труба представляет собой поток байтов. Поток этот имеет начало (исток)
и конец (приемник). В исток этого потока можно записывать данные, а из
приемника — считывать. Нить, которая пытается считать данные из пустой
трубы, будет задержана, пока там что-нибудь не появится. Наоборот, пишущая
нить может записать в трубу некоторое количество данных, прежде чем труба
заполнится, и дальнейшая запись будет заблокирована. На практике труба
реализована в виде небольшого (несколько килобайтов) кольцевого буфера.
Передатчик заполняет этот буфер, пока там есть место. Приемник считывает
данные, пока буфер не опустеет.
Трубу можно установить в режим чтения и записи без блокировки. При этом
вызовы, которые в других условиях были бы остановлены и вынуждены были
бы ожидать партнера на другом конце трубы, возвращают ошибку с особым
кодом.
По-видимому, трубы являются одной из первых реализаций гармонически взаимодействующих
процессов по терминологии Дейкстры.
Самым интересным свойством трубы является то, что чтение данных из и запись
в нее осуществляется теми же самыми системными вызовами read и write,
что и работа с обычным файлом, внешним устройством или сетевым соединением
(сокетом). На этом основана техника переназначения ввода-вывода, широко
используемая в командных интерпретаторах UNIX. Она состоит в том, что
большинство системных утилит получают данные из потока стандартного ввода
(stdin) и выдают их в поток стандартного вывода (stdout). При этом, указывая
в качестве этих потоков терминальное устройство, файл или трубу, мы можем
использовать в качестве ввода, соответственно: текст, набираемый с клавиатуры,
содержимое файла или стандартный вывод другой программы. Аналогично мы
можем выдавать данные сразу на экран, в файл или передавать их на вход
другой программы.
Так, например, компилятор GNU С состоит из трех основных проходов: препроцессора,
собственно компилятора, генерирующего текст на ассемблере, и ассемблера.
При этом внутри компилятора, на самом деле, также выполняется несколько
проходов по тексту (в описании перечислено восемнадцать), в основном для
оптимизации, но нас это в данный момент не интересует, поскольку все они
выполняются внутри одной задачи. При этом все три задачи объединяются
трубами в единую линию обработки входного текста — конвейер (pipeline),
так что промежуточные результаты компиляции не занимают места на диске.
В системе UNIX труба создается системным вызовом pipe(int flldes;2]) Этот
вызов создает трубу и помещает дескрипторы файлов, соответствующие входному
и выходному концам трубы, в массив fildes. Затем мы можем вы полнить fork,
в различных процессах переназначить соответствующие конць трубы на место
stdin и stdout и запустить требуемые программы (пример 7.7). При этом
мы получим типичный конвейер — две задачи, стандартный ввод и вывод которых
соединены трубой.
#include <unistd.h>
void pipeline(void) {
/* stage 1 */
int pipel[2];
int childl;
int pipe2[2];
int child2;
int child3;
pipe(pipel);
if ((childl=fork())==0) {
close(pipel[0]); /* Закрыть лишний конец трубы */
closed); /* Переназначить стандартный вывод */
dup(pipel[1]);
close(pipel[1]);
/* Исполнить программу */
execlpC'du", "du", "-s", ".", NULL);
/* Мы можем попасть сюда только при ошибке exec */
perror("Cannot exec");
exit(0);
}
close(pipel [1] ) ;
if (childl==-l) {
perror("Cannot fork");
}
/* stage 2 */
pipe(pipe2);
if ( (child2=fork() )==0) { '. close (0) ; /J" Переназначить стандартный
ввод */
dup(pipel[0]} ; close (pipel [0] ) ;
•'close (pipe2 [0] ) ; /* Закрыть лишний конец трубы */ close (1) ; /*
Переназначить стандартный вывод */
close (pipe2 [1] ) ;
/* Исполнить программу */
execlp ("sort", "sort", "-nr", NULL);
/* Мы можем попасть сюда только при ошибке exec */
perror ("Cannot exec");
exit(O) ;
}
close (pipel [0] ) ;
close (pipe2 [1] ) ;
if (child2==-l) {
perror ("Cannot fork");
}
/* stage 3 */
if ( (child3=fork() )==0) {
close (0) ; /* Переназначить стандартный ввод */
dup(pipe2 [0] ) ;
close (pipe2 [0] ) ;
/* Исполнить программу */
execlp ("tail", "tail", "-1", NULL) ;
/* Мы можем попасть сюда только при ошибке exec */
perror ("Cannot exec");
exit (0) ;
}
close (pipe2 [0] ) ;
if (child3==-l) {
perror ("Cannot fork");
}
while (wait (NULL) !=-!) ;
return ;
}
Понятно, что такие трубы можно использовать только для связи родственны
задач, т. е. таких, которые связаны отношением родитель-потомок или являются
потомками одного процесса.
Для связи между неродственными задачами используется другое средство.
именованные трубы (named pipes) в System V и UNIX domain sockets в BSD
UNIX. В разных системах именованные трубы создаются различными систем
ными вызовами, но очень похожи по свойствам, поэтому стандарт POSIX пред
лагает для создания именованных труб библиотечную функцию mkfifc
{c--ls. char * name, mode_t flags);. Эта функция создает специальный
файл" Открывая такой файл, программа получает доступ к одному из
концов трубы Когда две программы откроют именованную трубу, они смогут
использовать ее для обмена данными точно так же, как и обычную.
Современные системы семейства Unix предоставляют возможность для одновременной
работы с несколькими трубами (а также с другими объектами, описываемыми
дескриптором файла — собственно файлами, сокетами и т. д.)_, системный
вызов select. Этот вызов возвращает список дескрипторов файлов, которые
способны передать или принять данные. Если ни один из дескрипторов не
готов к обмену данными, select блокируется.
Трубы широко используются системами семейства Unix, и они внесены в стандарт
POSIX. Ряд операционных систем, не входящих в семейство Unix, например
VxWorks, также предоставляют этот сервис.
Почтовые ящики VMS
Система VMS предоставляет средства, отчасти аналогичные трубам, называемые
почтовые ящики (mailbox). Почтовый ящик также представляет собой кольцевой
буфер, доступ к которому осуществляется теми же системными вызовами, что
и работа с внешним устройством. Системная библиотека языка VAX С использует
почтовые ящики для реализации труб, в основном совместимые с UNIX и стандартом
POSIX. Широко используемый сервис сетевой передачи данных, сокеты протокола
TCP, также очень похожи на трубу.
Линки транспьютера
В микропроцессорах семейства Transputer микропрограммно реализованы линки
(link — связь) — синхронный примитив, отчасти похожий на трубы.
Линки бывают двух типов — физические и логические. Операции над линками
обоих типов осуществляются одними и теми же командами. Физический линк
представляет собой последовательный интерфейс RS432, реализованный на
кристалле процессора. С линком также ассоциировано одно слово памяти,
смысл которого будет объяснен далее.
Современные транспьютеры имеют четыре физических линка. Физические линки
могут передавать данные со скоростью до 20 Мбит/с и могут использоваться
как для соединения транспьютеров между собой (рис. 7.7), так и для подключения
внешних устройств. Благодаря этому физический линк может использоваться
как для связи между процессами на разных транспьютерах, так и для синхронизации
процесса с внешними событиями и даже просто для ввода-вывода.
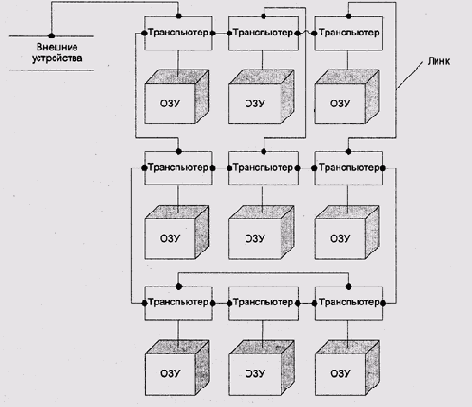
Рис. 7.7. Сеть транспьютеров, соединенных физическими линками
Логический линк— это просто структура данных, выделенная
в физическом адресном пространстве процессора. С точки зрения программы,
физический и логический линки ничем не отличаются, кроме того, что описатель
физического линка привязан к определенному физическому адресу. Логический
линк может использоваться только для связи между процессами (напоминаем,
что по принятой в транспьютере терминологии, нити называются процессами),
исполняющимися на одном транспьютере.
Транспьютер Т9000 предоставляет также виртуальные линки— протокол, позволяющий
двум транспьютерам организовать несколько линий взаимодействия через один
физический линк, или даже через цепочку маршрутизаторов.
При передаче данных в линк процесс должен исполнить команду out. Эта команда
имеет три операнда: адрес линка, адрес массива данных и количество данных.
Для передачи операндов используется регистровый стек процессора. Процесс,
исполнивший такую команду, задерживается до тех пор, пока все данные не
будут переданы (рис. 7.8).

Рис. 7.8. Передача данных через линк
Аналогично, при приеме данных из линка, процесс должен
исполнить команду in. Эта команда также имеет
три операнда — адрес линка, адрес буфера, куда необходимо поместить данные,
и размер буфера. При исполнении такой команды процесс блокируется до тех
пор, пока буфер не будет заполнен данными. При этом приемник и передатчик
могут использовать буферы разного размера, т. е. приемник может считывать
большой массив данных в несколько приемов и т. д.
Существует также команда alt, позволяющая процессу
ожидать данные из нескольких линков одновременно. В качестве одного из
ожидаемых событий можно также использовать сигнал от системного таймера.
Слово, связанное с линком, содержит указатель на дескриптор процесса,
ожидающего приема или передачи данных через линк. Кроме того, это слово
может принимать значение NotProcessP, указывающее,
что соединения никто не ждет. Остальная информация, такая, как указатель
на буфер и размер буфера, хранится в дескрипторе процесса.
Направление передачи данных определяется командой, которую исполнит очередной
процесс при обращении к линку. Например, если исполняется команда out,
предназначенные для записи данные копируются в буфер ожидающего процесса.
При этом указатель буфера продвигается, а счетчик размера уменьшается
на количество скопированных данных. Если же в линке записано значение
NotProcessP, процесс переводится в состояние
ожидания и указатель на его дескриптор помещается в линк (рис. 7.9).

Рис. 7.9. Алгоритм работы команд in и out
Аналогично обрабатываются запросы на чтение. Если мы имеем
более двух процессов, пытающихся использовать один линк, то возникает
серьезная проблема: внимательный читатель должен был заметить, что мы
не сказали, где хранится информация о том, чего ожидает текущий процесс:
чтения или записи. Проблема состоит в том, что эта информация нигде не
хранится. Если процесс попытается записать данные в линк, на котором кто-то
уже ожидает записи, то данные второго процесса будут записаны поверх данных
ожидавшего. Если размеры буферов совпадут, то ожидавший процесс будет
пребывать в убеждении, что он успешно передал все данные. Поэтому линки
рекомендуется использовать только для однонаправленной передачи данных
между двумя (не более!) процессами.
При работе с физическим линком данные не копируются, а передаются или
принимаются через физический канал в режиме прямого доступа к памяти.
Если на другом конце линка находится другой транспьютер, это все-таки
можно считать копированием, но к линку может быть подключено и какое-то
другое устройство.
В середине 90-х, в эпоху расцвета микропроцессоров этого семейства, фирма
Inmos поставляла широкий набор трэмов (trem — TRansputer Extension module)
— устройств ввода-вывода с линком в качестве интерфейса. В частности,
поставлялись трэмы, позволявшие подключить к транспьютеру через линк адаптеры
Ethernet или SCSI.
Взаимодействие с внешним устройством через линк позволяет транспьютеру
синхронизовать свою деятельность с этими устройствами без использования
механизма прерываний. В [INMOS 72 TRN 203 02] приводится пример программной
имитации векторных прерываний с передачей вектора по линку
и мониторным процессом, который принимает эти векторы из линка и вызывает
соответствующие обработчики.
Системы, управляемые событиями
В начале 70-х годов появилась новая архитектура многозадачных систем
довольно резко отличающаяся от вышеописанной модели последовательных процессов.
Речь идет о так называемых системах, управляемых
событиями (event-driven systems).
На первый взгляд, концепция систем, управляемых событиями, близко родственна
гармонически взаимодействующим процессам. Во всяком случае, одно из ключевых
понятий этой архитектуры, очередь событий, мы упоминали в числе средств
гармонического межпоточного взаимодействия. Различие между этими архитектурами
состоит, скорее, во взгляде на то, что представляет собой программа.
В модели гармонически взаимодействующих потоков процесс исполнения программного
комплекса представляет собой совокупность взаимодействующих нитей управления.
В системе, управляемой событиями, программа представляет собой совокупность
объектов, обменивающихся сообщениями о событиях,
а также реагирующих на сообщения, приходящие из внешних источников.
В идеале, объекты взаимодействуют между собой только через сообщения.
Приходящие сообщения побуждают объект изменить свое состояние и, возможно,
породить некоторое количество сообщений, предназначенных для других объектов.
При такой модели взаимодействия нам неважно, исполняются ли методы объектов
как параллельные (или псевдопараллельные) нити, или же последовательно
вызываются единой нитью, менеджером или диспетчером сообщений.
Впервые эта архитектура была реализована в экспериментальных настольных
компьютерах Alto, разработанных в 1973 году в исследовательском центре
PARC фирмы Xerox. Целью эксперимента было создание операционной среды,
удобной для создания интерактивных программ с динамичным пользовательским
интерфейсом.
В этих системах впервые была реализована многооконная графика, когда пользователь
одновременно видит на экране графический вывод нескольких программ и может
активизировать любую из них, указав на соответствующее окно при помощи
манипулятора-"мыши".
При каждом движении мыши, нажатии на ее кнопки или клавиши на клавиатуре
генерируется событие. События могут также генерироваться системным таймером
или пользовательскими программами. Нельзя не упомянуть "визуальные"
события, которые порождаются в ситуации, когда пользователь
сдвинул или закрыл одно из окон и открыл при этом часть окна, находившегося
внизу. Этому окну посылается событие, говорящее о том, что ему нужно перерисовать
часть себя (рис. 7.10).

Рис. 7.10. Визуальное событие
Каждое сообщение о событии представляет собой структуру данных, которая
содержит код, обозначающий тип события: движение мыши, нажатие кнопки
и т. д., а также поля, различные для различных типов событий. Для "мышиных"
событий — это текущие координаты мыши и битовая маска, обозначающая состояние
кнопок (нажата/отпущена). Для клавиатурных событий — это код нажатой клавиши,
обычно, ASCII-код символа для алфавитно-цифровых и специальные коды для
стрелок и других "расширенных" и "функциональных"
клавиш — и битовая маска, обозначающая состояние различных модификаторов,
таких как SHIFT, CNTRL, ALT и т. д. Для визуальных событий — это координаты
прямоугольника, который нужно перерисовать, и т. д.
Все сообщения о событиях помещаются в очередь в порядке их возникновения.
В системе существует понятие обработчика событий.
Обработчик событий Представляет собой объект, т. е. структуру данных,
с которой связано несколько подпрограмм — методов. Один из методов вызывается
при поступлении сообщения. Обычно он также называется обработчиком событий.
Некоторые системы предлагают объектам-обработчикам предоставлять различные
методы для обработки различных событий — например, метод onClick
будет вызываться, когда придет событие, сигнализирующее о том что кнопка
мыши была нажата и отпущена, когда курсор находился над областью, занимаемой
объектом на экране.
Рассмотрим объект графического интерфейса, например меню. При нажатии
на кнопку мыши в области этого меню вызывается обработчик события Он разбирается,
какой из пунктов меню был выбран, и посылает соответствующее командное
сообщение объекту, с которым ассоциировано меню Этот объект, в свою очередь,
может послать командные сообщения каким-то другим объектам. Например,
если была выбрана команда File/Open, меню передаст обработчику основного
окна приложения сообщение FILEOPEN, а тот, в свою очередь, может передать
команду Open объекту, отвечающему за отрисовку и обработку файлового диалога.
Таким образом, вместо последовательно исполняющейся программы, время от
времени вызывающей систему для исполнения той или иной функции, мы получаем
набор обработчиков, вызываемых системой в соответствии с желаниями пользователя.
Каждый отдельный обработчик представляет собой конечный автомат, иногда
даже вырожденный, не имеющий переменной состояния. Код обработчика и по
реализации обычно похож на конечный
автомат, и состоит m большого оператора switch,
выбирающего различные действия в зависимости от типа пришедшего сообщения
(пример 7.8).
Пример 7.8. Обработчик оконных событий в OS/2 Presentation Manager
/* фрагмент примера из поставки IBM Visual Age for C++
3.0.
* Обработчик событий меню предоставляется системой,
* а обработку командных событий, порождаемых меню,
* вынужден брать на себя разработчик приложения. */
/****************************************************************
Copyright (С) 1992 IBM Corporation
ОТКАЗ ОТ ГАРАНТИЙ. Следующий код представляет собой пример кода созданный
IBM Corporation. Этот пример кода не является частью ни одного стандарта
или продукта IBM и предоставляется вам с единственной целью — помочь в
разработке ваших приложений. Код предоставляется "КАК ЕСТЬ",
без каких-либо гарантий. IBM не несет ответственности за какие бы то ни
было повреждения, возникшие в результате использования вами этого кода,
даже если она и могла предполагать возможность таких повреждений.
/****************************************************************
* Имя: MainWndProc *
Описание: Оконная процедура главного окна клиента. *
* Концепции: Обрабатывает сообщения, посылаемые главному
окну клиента. Эта процедура обрабатывает основные сообщения, которые должны
обрабатывать все клиентские окна, и передает все остальные [функции] UserWndProc,
в которой разработчик может обработать любые другие
сообщения. *
API: He используются
* Параметры: hwnd — Идентификатор окна, которому адресовано сообщение
* msg — Тип сообщения
* mpl — Первый параметр сообщения
* тр2 — Второй параметр сообщения.
* Возвращаемое значение: определяется типом сообщения
*/
****************************************************************
MRESULT EXPENTRY MainWndProc(HWND hwnd, USHORT msg, MPARAM mpl,
MPARAM mp2)
{
switch(msg) {
case WM_CREATE:
return(InitMainWindow(hwnd, mpl, mp2)};
break;
case WM_PAINT:
«
MainPaint(hwnd); break;
case WM_COMMAND:
MainCommand(mpl,. mp2); break;
case WM_INITMENU:
Ini tMenu(mpl, mp2); break;
case HM_QUERY_KEYS_HELP:
return (MRESULT)PANEL_HELPKEYS;/* Вернуть Id панели подсказки ' break;
/*
* Все необработанные сообщения передаются
* пользовательской процедуре окна.
* Она отвечает за передачу всех необработанных
* сообщений функции WinDefWindowProc(); */
default:
return(UserWndProc(hwnd, msg, mpl, mp2)); break;
return (MRESULT)O; /* Все оконные процедуры должны по умолчанию возвращать
0 */
} /* Конец MainWndProc() */
/****************************************************************
* Имя: MainCommand
* Назначение: Главная процедура окна, обрабатывающая WM_COMMAND *
* Концепции: Процедура вызывается, когда сообщение WM_COMMAND
* отправляется главному окну. Оператор switch
* переключается в зависимости от id меню, которое
* породило сообщение и предпринимает действия,
* соответствующие этому пункту меню. Все id меню,
* не являющиеся частью стандартного набора команд,
* передаются пользовательской процедуре обработки
* WM_COMMAND.
* API : WinPostMsg *
* Параметры : mpl — Первый параметр сообщения
тр2 — Второй параметр сообщения *
* Возвращает: VOID *
\*************+**************************************************^
VOID MainCommand(MPARAM mpl, MPARAM mp2)
switch(SHORT1FROMMP(mpl))
I
case IDM_EXIT:
WinPostMsg( hwndMain, WM_QUIT, NULL, NULL break;
case IDM__FILENEW: FileNew(mp2); break;
case IDM_FILEOPEN: FileOpen(mp2); break;
case IDM_FILESAVE: FileSave(mp2); break;
case IDM_FILESAVEAS: FileSaveAs(mp2); break;
case IDM_EDITUNDO: EditUndo(mp2); break;
case IDM_EDITCUT: EditCut(mp2); break;
case IDM_EDITCOPY: EditCopy(mp2); break;
case IDM_EDITPASTE: EditPaste(mp2); break;
case IDM_EDITCLEAR: EditClear(mp2); break;
case IDM_HELPUSINGHELP: HelpUsingHelp(mp2); break;
case IDM_HELPGENERAL: HelpGeneral(mp2); break;
case IDM_HELPKEYS: HelpKeys(mp2); break;
case IDM_HELPINDEX: Helplndex(mp2); break;
case IDM_HELPPRODINFO: HelpProdInfo(mp2); break; /*
* Здесь вызывается пользовательская процедура
* обработки команд, чтобы обработать те id',
* которые еще не были обработаны. */
default:
UserCammand(mpl, mp2); break; )
} /* MainCommand() */
Специальная программа, менеджер событий (рис.
7.12), просматривает очередь и передает поступающие события обработчикам.
События, связанные с экранными координатами, передаются обработчику, ассоциированному
с соответствующим окном. Клавиатурные события передаются фокусу клавиатуры
— текущему активному обработчику клавиатуры.
Управление событиями позволяет относительно легко разрабатывать динамичные
пользовательские интерфейсы, привычные для пользователей современных графических
оболочек.
Высокая динамичность интерфейса проще всего обеспечивается, если каждый
обработчик быстро завершается. Если же в силу природы запрашиваемой операции
она не может завершиться быстро — например, если мы вставили символ, параграф
удлинился на строку, и в результате текстовому процессору Типа WYSIWYG
приходится переформатировать и переразбивать на страни-Цы весь последующий
текст — мы можем столкнуться с проблемой.

Рис. 7.12. Менеджер и обработчики событий
В такой ситуации (а при написании реальных приложений она возникает
сплошь и рядом) мы и вынуждены задуматься о том, что же в действительности
представляют собою обработчики — процедуры, синхронно вызываемые единственной
нитью менеджера событий, или параллельно исполняющиеся нити. Первая стратегия
называется синхронной обработкой сообщений,
а вторая, соответственно, — асинхронной.
Графические интерфейсы первого поколения — Mac OS, Winl6 — реализовывали
синхронную обработку сообщений, а когда обработчик задумывался надолго,
рисовали неотъемлемый атрибут этих систем — курсор мыши в форме песочных
часов.
Несколько более совершенную архитектуру предлагает оконная подсистема
OS/2, Presentation Manager. PM также реализует синхронную стратегию обработки
сообщений (менеджер событий всегда ждет завершения очередного обработчика),
но в системе, помимо менеджера событий, могут существовать и другие нити.
Если обработка события требует длительных вычислений или других действий
(например, обращения к внешним устройствам или к сети), рекомендуется
создать для этого отдельную нить и продолжить обработку асинхронно. Если
же приложение этого не сделает (например, обработчик события просто зациклится
или заснет на семафоре), системная очередь сообщений будет заблокирована
и ни одно из графических приложений не сможет работать. Современные версии
РМ предоставляют в этом случае возможность отцепить "ненормальное"
приложение от очереди или паже принудительно завершить его.
Асинхронные очереди сообщений предоставляют Win32 и оконная система X
Window. Впрочем, и при асинхронной очереди впавший в философские размышления
однопоточный обработчик событий — тоже малоприятное зрелище, ведь он не
может перерисовать собственное окно, поэтому передвижение других окон
по экрану порождает любопытные спецэффекты (к сожалению, запечатлеть эти
эффекты при помощи утилит сохранения экрана невозможно — все известные
автору средства дожидаются, пока все попавшие в сохраняемую область окна
перерисуются. А фотографии монитора обычно имеют низкое качество). Разработчикам
приложений для названных систем также рекомендуется выносить длительные
вычисления в отдельные нити.
Большинство реальных приложений для современных ОС, имеющих пользовательский
интерфейс, таким образом, имеют двух- или более слойную архитектуру. При
этом архитектура ближайшего к пользователю стоя (frontend),
как правило, тяготеет к событийно-управляемой, а следующие слои (backend)
обычно состоят из более традиционных взаимодействующих (не всегда, впрочем,
строго гармонически) параллельно исполняющихся нитей, зачастую даже разнесенных
по разным вычислительным системам.
