Теория операционных систем
Загрузка программ
Выяснив, что представляет собой программа, давайте рассмотрим
процедуру ее загрузки в оперативную память компьютера (многие из обсуждаемых
далее концепций, впрочем, в известной мере применимы и к прошивке программы
в ПЗУ).
Для начала предположим, что программа была заранее собрана в некий единый
самодостаточный объект, называемый загрузочным
или загружаемым модулем. В ряде операционных
систем программа собирается в момент загрузки из большого числа отдельных
модулей, содержащих ссылки друг на друга, но об этом ниже.
Для того чтобы не путаться, давайте будем называть программой
ту часть загрузочного модуля, которая содержит исполняемый код. Результат
загрузки программы в память будем называть процессом
или, если нам надо отличать загруженную программу от процесса ее исполнения,
образом процесса. К образу процесса иногда
причисляют не только код и данные процесса (подвергнутые преобразованию
как в процессе загрузки, так и в процессе работы программы), но и системные
структуры данных, связанные с этим процессом. В старой литературе процесс
часто называют задачей.
В системах с виртуальной памятью каждому процессу обычно выделяется свое
адресное пространство, поэтому мы иногда будем употреблять термин процесс
и в этом смысле. Впрочем, во многих системах значительная часть эдресных
пространств разных процессов перекрывается — это используется Для реализации
разделяемого кода и данных.
В рамках одного процесса может исполняться один или несколько потоков
или нитей управления. Это понятие будет
подробнее разбираться в главе 8.
Некоторые системы предоставляют и более крупные структурные единицы, Чем
процесс. Например, в системах семейства Unix существуют группы процессов,
которые используются для реализации логического объединенияют не только
код и данные процесса (подвергнутые преобразованию как в процессе загрузки,
так и в процессе работы программы), но и системные структуры данных, связанные
с этим процессом. В старой литературе процесс часто называют задачей.
В системах с виртуальной памятью каждому процессу обычно выделяется свое
адресное пространство, поэтому мы иногда будем употреблять термин процесс
и в этом смысле. Впрочем, во многих системах значительная часть эдресных
пространств разных процессов перекрывается — это используется Для реализации
разделяемого кода и данных.
В рамках одного процесса может исполняться один или несколько потоков
или нитей управления. Это понятие будет подробнее разбираться в главе
8.
Некоторые системы предоставляют и более крупные структурные единицы, чем
процесс. Например, в системах семейства Unix существуют группы процессов,
которые используются для реализации логического объединения процессов
в задания (job). Ряд систем имеют также понятие сессии — совокупности
всех заданий, которые пользователь запустил в рамках одного сеанса работы.
Впрочем, соответствующие концепции часто плохо определены, а их смысл
сильно меняется от одной ОС к другой, поэтому мы практически не будем
обсуждать эти понятия.
В более старых системах и в старой литературе называют результат загрузки
задачей, а процессами — отдельные нити управления.
Однако в наиболее распространенных ныне ОС семейств Unix и Win32, принято
задачу называть процессом, а процесс — нитью (tread).
Этой терминологии мы и будем придерживаться, кроме тех случаев, когда
будем обсуждать примеры из жизни ОС, в которой принята иная терминология.
Создание процессов в Unix
В системах семейства Unix новые процессы создаются системным вызовом fork.
Этот вызов создает два процесса, образы которых в первый момент полностью
идентичны, у них различается только значение, возвращенное вызовом fork.
Типичная программа, использующая этот вызов, выглядит так, как представлено
в примере 3.1.
При этом каждый из процессов имеет свою копию всех локальных и статических
переменных. На процессорах со страничным диспетчером памяти физического
копирования не происходит. Изначально оба процесса используют одни и те
же страницы памяти, а дублируются только те из них, которые были изменены.
На системах, не имеющих страничного или сегментного диспетчера памяти,
fork требует копирования адресных пространств, что приводит к большим
накладным расходам, да и просто не всегда возможно.
Если мы хотим запустить другую программу, то мы должны исполнить системный
вызов из семейства exec. Вызовы этого семейства различаются только способом
передачи параметров. Все они прекращают исполнение текущего образа процесса
и создают новый процесс с новым виртуальным адресным пространством, но
с тем же идентификатором процесса. При этом у нового процесса будет тот
же приоритет, будут открыты те же файлы (это часто используется), и он
унаследует ряд других важных характеристик.
Несколько неожиданное, но тем не менее верное описание действия exec —
это замена образа процесса в рамках того же самого процесса.
Запуск другой программы в UNIX выглядит примерно так, как представлено
в примере 3.2.
Программа в примере 3.2 запускает командный интерпретатор /bin/sh, известный
как Bourne shell, приказывает ему исполнить команду Is -1 и перенаправляет
стандартный вывод этой команды в файл ls.log.
Техника программирования, основанная на fork/exec, несколько отличается
от принятой во многих других современных системах, в том числе Win32,
где при создании нового процесса мы сразу же указываем программу, которую
он будет исполнять.
Пример 3.1. Создание процесса в системах семейства Unix
;nt pid; /* Идентификатор порожденного процесса */
switch(pid = fork())
I
case 0: /* Порожденный процесс */
break; case -1: /Ошибка */
perror("Cannot fork");
extt(l) ; default: /* Родительский процесс */
/* Здесь мы можем ссылаться на порожденный процесс,
* используя значение pid */
Пример 3.2. Создание процесса и замена программы в системах семейства Unix
int pid; /* Идентификатор порожденного процесса */
switch (pid = fork () )
{
case 0: /* Порожденный процесс */
dup2(l, open("Is.log", 0_WRONLY I 0_CREAT)); /* Перенаправить
открытый файл #1 * (stdout) в файл Is.log */
execl("/bin/sh", "sh", "-c", "Is",
"-1", 0);
/* Сюда мы попадаем только при ошибке! */
/* fall through */ case -1: /* Ошибка */
perror("Cannot fork or exec");
exit(1); default: /* Родительский процесс */
/* Здесь мы можем ссылаться на порожденный
* процесс, используя значение pid */
}
Но вернемся к способам загрузки программ.
Абсолютная загрузка
Первый, самый простой, вариант состоит в том, что мы всегда будем загружать программу с одного и того же адреса. Это возможно в следующих случаях.
Система может предоставить каждому процессу свое адресное пространство. Это возможно только на процессорах, осуществляющих трансляцию виртуального адреса в физический. Система может исполнять в каждый момент только один процесс. Так ведет себя СР/М, так же устроено большинство загрузочных мониторов для самодельных компьютеров. Похожим образом устроена система RT-11, но о ней чуть ниже. Загрузочный файл, используемый при таком способе загрузки,
называется абсолютным загрузочным модулем.
Начальное содержимое образа процесса формируется путем простого копирования
модуля в память. В системе RT-11 такие файлы имеют расширение sav от saved
— сохраненный.
Формат загрузочного модуля a.out
В системе UNIX на 32-разрядных машинах также используется абсолютная загрузка.
Загружаемый файл формата a.out (современные версии Unix используют более
сложный формат загружаемого модуля и более сложную схему загрузки, которая
будет обсуждаться в разд. Разделяемые
библиотеки) начинается с заголовка (рис. 3.1), который содержит:
• "магическое число" — признак того, что это именно загружаемый
модуль, а не что-то другое;
• число TEXT_SIZE — длину области кода программы (TEXT);
• DATA_SIZE —длину области инициализованных данных программы (DATA);
• BSS_SIZE —длину области неинициализованных данных программы (BSS);
• стартовый адрес программы.
За заголовком следует содержимое областей TEXT и DATA. Затем может следовать
отладочная информация. Она нужна символьным отладчикам, но самой программой
не используется.
При загрузке система выделяет процессу TEXT_SIZE байтов виртуальной памяти,
доступной для чтения/исполнения, и копирует туда содержимое сегмента TEXT.
Затем отсчитывается DATA_SIZE байтов памяти, доступной для чтения/ записи,
и туда копируется содержимое сегмента DATA. Затем отсчитывается
еще BSS_SIZE байтов памяти, доступной для чтения/записи, которые прописываются
нулями.
Очистка выделяемой памяти нужна не столько для удобства программиста,
сколько по соображениям безопасности: перед вновь загружаемым процессом
эту память могли занимать (а при сколько-нибудь длительной работе системы
почти наверняка занимали) другие процессы, которые могли использовать
эту память для хранения важных и секретных данных, например паролей или
ключей шифрования.
После этого выделяется пространство под стек, в стек помещаются позиционные
аргументы и среда исполнения (environment), и управление передается на
стартовый адрес. Процесс начинает исполняться.

Рис. З.1. Загрузочный модуль a.out
Разделы памяти
Одним из способов обойти невозможность загружать более
одной програм-Mbi при абсолютной загрузке являются разделы памяти. В наше
время этот метод практически не применяется, но в машинах второго поколения
использовался относительно широко и часто описывается в старой литературе.
Идея метода состоит в том, что мы задаем несколько допустимых стартовых
адресов для абсолютной загрузки. Каждый такой адрес определяет раздел
памяти (рис. 3.2). Процесс может размещаться в одном разделе, или, если
это необходимо — т. е. если образ процесса слишком велик — в нескольких
Это позволяет загружать несколько процессов одновременно, сохраняя при
этом преимущества абсолютной загрузки

Рис. 3.2. Разделы памяти
Если мы не знаем, в какой из разделов пользователь вынужден будет загружать нашу программу, мы должны предоставить по отдельному загрузочному модулю на каждый из допустимых разделов. Понятно, что это не очень практично, поэтому разделы были вытеснены более удобными схемами управления памятью.
Относительная загрузка
Относительный способ загрузки
состоит в том, что мы загружаем программу каждый раз с нового адреса.
При этом мы должны настроить ее на новые адреса, а для этого нам надо
вспомнить материал предыдущей главы и понять, что же именно в программе
привязано к адресу загрузки.
При использовании в коде программы абсолютной адресации мы должны найти
адресные поля всех команд, использующих такую адресацию, и пересчитать
эти адресные поля с учетом реального адреса загрузки (рис. 3.3). Если
в коде программы применялись косвенно-регистровый, базовый и ба-зово-индексный
режимы адресации, следует найти те места, где в регистр загружается значение
адреса (рис. 3.4).

Рис. 3.3. Перемещение кода, использующего абсолютную адресацию

Рис. З.4. Перемещение кода, самостоятельно перезагружающего базовые регистры
Сложность здесь в том, что если абсолютные адресные поля
можно найти анализом кодов команд (деассемблированием), то значение в
адресный регистр может загружаться задолго до собственно адресации, причем,
как мы видели в примерах кода для процессора SPARC, Формирование значения
регистра может происходить и по частям. Без помощи программиста или компилятора
(в этой главе мы не будем различать написанный на ассемблере или компилированный
код, а того, кто генерировал код, будем называть программистом) решить
вопрос о том, какая из команд загружает в регистр скалярное значение,
а какая -будущий адрес или часть адреса, невозможно. Та же проблема возникает
в случае, если мы используем в качестве указателя ячейку статически инициализованных
данных (пример 3.3).
Пример 3.3. Примеры статически инициализованных указателей
в С
int buf[20], *bufptr=buf;
char * message="No message defined yet\n";
void do_nothing_hook(int);
void (*hook)(int)=do_nothing_hook;
Довольно легко построить и пример кода, в котором адресация происходит вообще без явного использования каких-либо регистров, во всяком случае, без загрузки в них значений (пример 3.4).
Пример 3.4. Реализация косвенного перехода по адресу dst_seg:dst_offs
push dst seg ; Это и будет ссылкой на абсолютный адрес
push dst_offs
retf
На практике содействие программиста загрузчику состоит
в том, что программист старается без необходимости не использовать в адресных
полях и в качестве значений адресных регистров произвольные значения (необходимость
в этом может возникать при адресации системных структур данных или внешних
устройств, расположенных по фиксированным адресам). Вместо этого, программист
применяет ассемблерные символы, соответствующие адресам.
Ассемблер при каждой ссылке на такой символ генерирует не только "заготовку"
адреса в коде, но и запись в таблице перемещений
(relocation table). Эта запись хранит место ссылки на такой символ
в коде или данных. Если в ссылке используется только часть адреса, как
в командах sethi %10, %hi(addr)
процессора SPARC, или move ax, segment
addr Процессора 8086, мы запоминаем и этот факт.
В качестве "заготовки" адреса обычно используется смешение адресуемого
объекта от начала программы. При настройке программы на реальный адрес
загрузки нам, таким образом, необходимо пройти по всем объектам, перечисленным
в таблице перемещений, и переместить каждую из ссылок — сформировать из
заготовки адрес.
Файл, содержащий таблицу перемещений, гораздо сложнее абсолютного загружаемого
модуля и носит название относительного или перемещаемого загрузочного
модуля. Именно такой формат имеют ехе-файлы в системе MS DOS (пример 3.5).
Пример 3.5. Заголовок ЕХЕ-файла MS DOS. Цитируется по WINT.H из поставки | ; MS Visual C++ v6.0 (перевод комментариев автора)
#define IMAGE_DOS_SIGNATURE Ox4D5A // MZ
typedef struct _IMAGE_DOS_HEADER { // Заголовок DOS .EXE
WORD e_magic; // Магическое число (сигнатура)
WORD e_cblp; // Длина последней страницы файла в байтах
WORD e_cp; // Количество страниц в файле
WORD e_crlc; // Количество перемещений
WORD e_cparhdr; // Размер заголовка в параграфах
WORD ejrainalloc; // Минимальное количество дополнительных параграфов
ORD e_maxalloc; // Максимальное количество дополнительных параграфов
WORD e ss; // Начальное (относительное) значение SS
WORD e_sp; // Начальное значение SP
WORD e_csum; // Контрольная сумма
WORD e_ip; // Начальное значение IP
WORD e_cs; // Начальное (относительное) значение CS
WORD e_lfarlc;// Адрес таблицы перемещений в файле
WORD e_ovno;// Номер перекрытия
WORD e_res[4];// Зарезервировано
WORD e_oemid; // OEM идентификатор (для e_oeminfo)
WORD e_oeminfo;// Информация OEM; специфично для e_oemid
WORD e_res2[10];// Зарезервировано
LONG e_lfanew; }// Адрес следующего заголовка в файле
}IMAGE DOS HEADER, РIMAGE DOS HEADER;
Наиболее поучительна в этом отношении система RT-11,
в которой существуют загружаемые модули обоих типов. Обычные программы
имеют расширение sav, представляют собой абсолютные загружаемые модули
и грузятся всегда с адреса 01000. Ниже этого магического адреса находятся
векторы прерываний и стек программы. Сама операционная система вместе
с драйверами размещается в верхних адресах памяти. Естественно, вы не
можете загрузить одновременно два sav-файла.
Однако, если вам обязательно нужно исполнять одновременно две программы,
вы можете собрать вторую из них в виде относительного модуля: файла с
расширением rel. Такая программа будет загружаться в верхние адреса памяти,
каждый раз разные, в зависимости от конфигурации ядра системы, количества
загруженных драйверов устройств и других rel-модулей (рис. 3.5).

Рис. 3.5. Распределение памяти в RT-11 с одним загруженным sav-файлом и двумя rel-файлами
Базовая адресация
Впрочем, если уж мы полагаемся на содействие программиста, можно пойти в этом направлении дальше: мы объявляем один или несколько регистров процессора базовыми (несколько регистров могут использоваться для адресации различных сегментов программы, например, один — для кода, другой — для статических данных, третий — для стека) и договариваемся, что значения этих регистров программист принимает как данность и никогда сам не модифицирует, зато все адреса в программе он вычисляет на основе значений этих регистров (рис. 3.6).

Рис. З.6. Перемещение кода, использующего базовую адресацию
В этом случае для перемещения программы нам нужно только
изменить значения базовых регистров, и программа даже не узнает, что загружена
с Другого адреса. Статически инициализованными указателями в этом случае
пользоваться либо невозможно, либо необходимо всегда прибавлять к ним
значения базовых регистров.
Именно так происходит загрузка corn-файлов в системе MS DOS. Система вьщеляет
свободную память, настраивает для программы базовые регистры DS и CS,
которые почему-то называются сегментными, и передает управление на стартовый
адрес. Ничего больше делать не надо.
Позиционно-независимый код
За всеми этими разговорами мы чуть было не забыли о
третьем способе формирования адреса в программе. Это относительная адресация,
когда адрес получается сложением адресного поля команды и адреса самой
этой команды — значения счетчика команд. Код, в котором используется только
такая адресация, можно загружать с любого адреса без всякой перенастройки.
Такой код называется позиционно-независимым (position-independent).
Позиционно-независимые программы очень удобны для загрузки, но, к сожалению,
при их написании следует соблюдать довольно жесткие ограничения, накладываемые
на используемые в программе методы адресации. Например, нельзя пользоваться
статически инициализованными переменными указательного типа, нельзя делать
на ассемблере фокусы, вроде того, который был приведен в примере 3.5,
и т. д. Возникают сложности при сборке программы из нескольких модулей.
К тому же, на многих процессорах, например, на Intel 8080/8085 или многих
современных RISC-процессорах, описанная выше реализация позиционно-независимого
кода вообще невозможна, так как эти процессоры не поддерживают соответствующий
режим адресации для данных. На процессорах гарвардской архитектуры адресовать
данные относительно счетчика команд вообще невозможно — команды находятся
в другом адресном пространстве.
Поэтому такой стиль программирования используют только в особых случаях.
Например, многие вирусы для MS DOS и драйверы для RT-I1 написаны именно
таким образом.
Любопытное наблюдение
В эпоху RT-11 хакеры писали драйверы. Сейчас они пишут вирусы. Еще любопытнее,
что для некоторых персональных платформ, например, для Amiga, вирусов
почти нет. Хакеры считают более интересным писать игры или демонстрационные
программы для Amiga. Похоже, общение с IBM PC порождает у программиста
какие-то агрессивные комплексы. Наблюдение это принадлежит не автору:
см. [КомпьютерПресс 1993].
Позиционно-независимый код в современных
Unix-системах
Компиляторы современных систем семейства UNIX — GNU С или стандартный
С-компилятор UNIX SVR4 имеют ключ -f PIC (Position-Independent Code).
Впрочем, код, порождаемый при использовании этого ключа, не является позиционно-независимым
в указанном выше смысле: этот код все-таки содержит перемещаемые адресные
ссылки. Задача состоит не в том, чтобы избавиться от таких ссылок полностью,
а лишь в том, чтобы собрать все эти ссылки в одном месте и разместить
их, по возможности, отдельно от кода. Какая от этого польза, мы поймем
несколько позже, в разд. Разделяемые
библиотеки, а сейчас обсудим технические приемы, используемые для
решения этой задачи.
Код, генерируемый GNU С, использует базовую адресацию: в начале функции
адрес точки ее входа помещается в один из регистров, и далее вся адресация
других функций и данных осуществляется относительно этого регистра. На
процессоре х86 используется регистр %ebx, а загрузка адреса осуществляется
командами, вставляемыми в пролог каждой функции (пример 3.6).
На процессорах, где разрешен прямой доступ к счетчику команд, соответствующий
код выглядит проще, но принцип сохраняется: компилятор занимает один регистр
и благодаря этому упрощает работу загрузчику.
Как мы видим в примере 3.7, на самом деле адресация происходит не относительно
точки входа в функцию, а относительно некоторого объекта, называемого
GOT или GLOBAL_OFFSET_TABLE. Счетчик команд используется для вычисления
адреса этой таблицы, а не сам по себе. Подробнее мы разберемся с логикой
работы этого кода (и заодно с тем, что означает еще один непонятный символ
— PLT) в разд. Разделяемые библиотеки.
Компилированный таким образом код предназначен в первую очередь для разделяемых
библиотек формата ELF (Executable and Linking Format, формат исполняемых
и собираемых [модулей], используемый большинством современных систем семейства
Unix).
Пример 3.6. Получение адреса точки входа в позиционно-независимую подпрограмму
call L4
L4:
popl %ebx
Пример 3.7. Позиционно-независимый код, порождаемый компилятором GNU С
/* strerror.c (emx+gcc) — Copyright (с) 1990-1996 by Eberhard
Mattes */
#include <stdlib.h>
#include <string.h>
#include <emx/thread.h>
char *strerror (int errnum)
{ (
if (errnum >= 0 && errnum < _sys_nerr)
return (char *)_sys_errlist [errnum];
else
{
static char msg[] = "Unknown error ";
#if defined ( _ MT _ )
struct _thread *tp = _thread ( ) ;
#define result (tp->_th_error)
#else
static char result [32];
#endif
memcpy (result, msg, sizeof (rasg) — 1) ;
_itoa (errnum, result + sizeof (msg) — 1, 10) ;
return result;
}
}
gcc -f PIC -S strerror.c
. file "strerror"
gcc2_compiled. :
_ gnu_compiled_c :
.data
_msg.2:
.ascii "Unknown error \0"
.Icomm _result.3,32
.text
.align 2, 0x90
. globl _strerror
__strerror:
pushl %ebp
movl %esp, %ebp
pushl %ebx
call L4
L4:
popl %ebx
addl $_GLOBAL_OFFSET_TABLE_+ [ . -L4 ] , %ebx
cmpl $0,8 (%ebp)
jl L2
movl _ sys_nerr@GOT (%ebx) , %eax
movl 8 (%ebp) , %edx
cmpl %edx, (%eax)
jle L2
movl 8(%ebp),%eax
movl %eax,%edx
leal 0(,%edx,4),%eax
movl __sys_errlist@GOT(%ebx) , %edx
movl (%edx,%eax),%eax jmp LI
.align 2,0x90 jmp L3 .align 2,0x90
L2:
pushl $14
leal _msg.2@GOTOFF(%ebx),%edx
movl %edx,%eax
pushl %eax
leal _result.3@GOTOFF(%ebx) ,%edx
movl %edx,%eax
pushl %eax
call _memcpy@PLT
addl $12,%esp
pushl $10
leal _result.3@GOTOFF(%ebx) , %edx
leal 14(%edx),%eax
pushl %eax
movl 8(%ebp),%eax
pushl %eax
call __itoa@PLT
addl $12,%esp
leal _result.3@GOTOFF(%ebx) ,%edx
movl %edx,%eax
jmp LI
.align 2,0x90
L3:
LI:
movl -4 (%ebp),%ebx
leave
ret
Оверлеи (перекрытия)
Еще более интересный способ загрузки программы — это оверлейная загрузка (over-lay, лежащий сверху) или, как это называли в старой русскоязычной литературе, перекрытие. Смысл оверлея состоит в том, чтобы не загружать программу в память целиком, а разбить ее на несколько модулей и помещать их в память по мере необходимости. При этом на одни и те же адреса в различные моменты времени будут отображены разные модули (рис. 3.7). Отсюда и название.

Рис. 3.7. Образ процесса с несколькими оверлеями
Потребность в таком способе загрузки появляется, если
у нас виртуальное адресное пространство мало, например 1 Мбайт или даже
всего 64 Кбайт (на некоторых машинах с RT-11 бывало и по 48 Кбайт, и многие
полезные программы нормально работали!), а программа относительно велика.
На современных 32-разрядных системах виртуальное адресное пространство
обычно измеряется гигабайтами, и большинству программ этого хватает, а
проблемы с нехваткой можно решать совсем другими способами. Тем не менее,
существуют различные системы, даже и 32-разрядные, в которых нет устройства
управления памятью, и размер виртуальной памяти не может превышать объема
микросхем ОЗУ, установленных на плате. Пример такой системы — упоминавшийся
выше транспьютер.
Важно подчеркнуть, что, несмотря на определенное сходство между задачами,
решаемыми механизмом перекрытий и виртуальной адресацией, одно ни в коем
случае не является разновидностью другого. При виртуальной адресации мы
решаем задачу отображения большого адресного пространства на ограниченную
оперативную память. При использовании оверлея мы решаем задачу отображения
большого количества объектов в ограниченное адресное пространство.
Основная проблема при оверлейной загрузке состоит в следующем: прежде
чем ссылаться на оверлейный адрес, мы должны понять, какой из оверлейных
модулей в данный момент там находится. Для ссылок на функции это просто:
вместо точки входа функции мы вызываем некую процедуру, называемую менеджером
перекрытий (overlay manager). Эта процедура знает, какой модуль
куда загружен, и при необходимости "подкачивает" то, что загружено
не было. Перед каждой ссылкой на оверлейные данные мы должны выполнять
аналогичную процедуру, что намного увеличивает и замедляет программу.
Иногда такие действия возлагаются на программиста (Win 16, Mac OS до версии
10 — подробнее управление памятью в этих системах описывается в разд.
Управление памятью в MacOS и Win 16),
иногда — на компилятор (handle pointer в Zortech C/C++ для MS DOS), но
чаще всего с оверлейными данными вообще предпочитают не иметь дела. В
таком случае оверлейным является только код.
В старых учебниках по программированию и руководствах по операционным
системам уделялось много внимания тому, как распределять процедуры между
оверлейными модулями. Действительно, загрузка модуля с диска представляет
собой довольно длительный процесс, поэтому хотелось бы минимизировать
ее. Для этого нужно, чтобы каждый оверлейный модуль был как можно более
самодостаточным. Если это невозможно, стараются вынести процедуры, на
которые ссылаются из нескольких оверлеев, в отдельный модуль, называемый
резидентной частью или резидентным
ядром. Это модуль, который всегда находится в памяти и не разделяет
свои адреса ни с каким другим оверлеем. Естественно, оверлейный менеджер
должен быть частью этого ядра.
Каждый оверлейный модуль может быть как абсолютным, так и перемещаемым.
От этого несколько меняется устройство менеджера, но не более того. На
архитектурах типа i80x86 можно делать оверлейные модули, каждый из которых
адресуется относительно значения базового регистра
cs и ссылается на данные, статически размещенные в памяти, относительно
постоянного значения регистра DS. Такие модули можно загружать в память
с любого адреса, может быть, даже вперемежку с данными. Именно так и ведут
себя оверлейные менеджеры компиляторов Borland и Zortech.
Сборка программ
| Он был ловкий и весь такой собранный джентльмен,
и одет — в самые лучшие и дорогие одежды; и все у него было подобрано
и пригнано, даже части тела. А. Тутуола |
В предыдущем разделе шла речь о типах исполняемых модулей,
но не говорилось ни слова о том, каким образом эти модули получаются.
Вообще говоря, способ создания загружаемого модуля различен в различных
ОС, но в настоящее время во всех широко распространенных системах этот
процесс выглядит примерно одинаково. Это связано, прежде всего, с тем,
что эти системы используют одни и те же языки программирования и правила
межмодульного взаимодействия, в которых явно или неявно определяют логику
раздельной компиляции и сборки.
В большинстве современных языков программирования программа состоит из
отдельных слабо связанных модулей. Как правило, каждому такому модулю
соответствует отдельный файл исходного текста. Эти файлы независимо обрабатываются
языковым процессором (компилятором), и для каждого из них генерируется
отдельный файл, называемый объектным модулем.
Затем запускается программа,- называемая редактором
связей, компоновщиком или линкером (linker
— тот, кто связывает), которая формирует из заданных объектных модулей
цельную программу.
Объектный модуль отчасти похож по структуре на перемещаемый загрузочный
модуль. Дело в том, что сборку программы из нескольких модулей можно уподобить
загрузке в память нескольких программ. При этом возникает та же задача
перенастройки адресных ссылок, что и при загрузке относительного загрузочного
файла (рис. 3.8). Поэтому объектный модуль должен в той или иной форме
содержать таблицу перемещений. Можно, конечно, потребовать, чтобы весь
модуль был позиционно-независимым, но это, как говорилось выше, накладывает
очень жесткие ограничения на стиль программирования, а на многих процессорах
(например Intel 8085) просто невозможно.
Кроме ссылок на собственные метки, объектный модуль имеет право ссылаться
на символы, определенные в других модулях. Типичный пример такой ссылки
— обращение к функции, которая определена в другом файле исходного текста
(рис. 3.9 и 3.10).

Рис. 3.8. Сборка программы
Для разрешения внешних ссылок мы должны создать две
таблицы: в одной перечислены внешние объекты, на которые ссылается модуль,
в другой — объекты, определенные внутри модуля, на которые можно ссылаться
извне. Обычно с каждым таким объектом ассоциировано имя, называемое глобальным
символом. Как правило, это имя совпадает с именем соответствующей
Функции или переменной в исходном языке.
Для каждой ссылки на внешний символ мы должны уметь определить, является
эта ссылка абсолютной или относительной, либо это вообще должна быть разность
или сумма двух или даже более адресов, и т. д. Для определения объекта,
с другой стороны, мы должны уметь указать, что это абсолютный Или перемещаемый
символ, либо что он равен другому символу плюс заданное смещение, и т.
д.

Рис. 3.9. Разрешение внешних ссылок (объектный модуль)
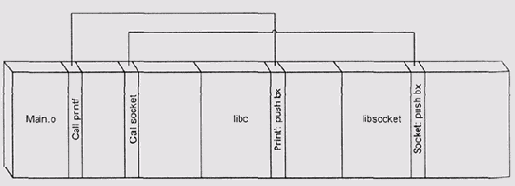
Рис. 3.10. Разрешение внешних ссылок (собранная программа)
Кроме того, в объектных файлах может содержаться отладочная информация,
формат которой может быть очень сложным. Следовательно, объектный файл
представляет собой довольно сложную и рыхлую структуру. Размер собранной
программы может оказаться в два или три раза меньше суммы длин объектных
модулей.
Типичный объектный модуль содержит следующие структуры данных.
Как правило, код и данные разбиты на именованные секции. В masm/tasm (MASM — Microsoft Assembler, Tasm — Turbo Assembler) такие секции называются сегментами, в DЕС'овских и UNIX'oвых ассемблерах — программными секциями (psect). В готовой программе весь код или данные, описанный в разных модулях, но принадлежащий к одной секции, собирается вместе. Например, в системах семейства Unix программы, написанные на языке С, состоят из минимум трех программных секций:
.text — исполняемый код (современные компиляторы иногда помещают в эту секцию и данные, описанные как const); .data — статически инициализированные данные; .bss — неинициализированные данные. В качестве упражнения читателю предлагается найти эти секции в примере
3.7.
Некоторые форматы объектных модулей, в частности ELF (Executable and Linking
Format — формат исполняемых и собираемых [модулей], используемый современными
системами семейства Unix), предоставляют особый тип глобального символа
— слабый (weak) символ (пример 3.8). При сборке
программы компоновщик не выдает сообщения об ошибке, если обнаруживает
Два различных определения такого символа, при условии, что одно из определений
является слабым — таким образом, слабый символ может быть легко переопределен
при необходимости. Особенно полезен этот тип при помещении объектного
модуля в библиотеку.
Пример 3.8. Структуры данных объектного модуля ELF (цитируется по elf.h из поставки Linux 2.2.16, перевод комментариев автора)
' Заголовок файла ELF. Находится в начале каждого
файла ELF. */
#define El NIDENT (16)
typedef struct
unsigned char e_ident[EI_NIDENT]; /* Магическое число и другая информация
*/
Elf32_Half e_type; Elf32_Half e_machine; Elf32_Word e_version; Elf32_Addr
e_entry; Elf32_0ff e_phoff;
Elf32_0ff e_shoff; Elf32_Word e_flags; Elf32_Half e_ehsize; Elf32__Half
e_phentsize;
Elf32_Half e_phnum; /* Elf32_Half e_shentsize; Elf32_Half e_shnum; /*
Elf32_Half e^shstrndx; ков секций */
} Elf32 Ehdr;
/* Тип объектного файла */
/* Архитектура */
/* Версия объектного файла */
/* Виртуальный адрес точки входа */
/* Смещение таблицы заголовка программы */
/* в файле */
/* Смещение таблицы заголовков секций в файле */
/* Процессорно-зависимые флаги */
/* Размер заголовка ELF в байтах */
/* Размер элемента */
/* таблицы заголовка программы */
Счетчик элементов таблицы заголовка программы */
/* Размер элемента таблицы заголовков секций */
Счетчик элементов таблицы заголовков программ */
/* Индекс таблицы имен секций в таблице заголов-
/* Поля в массиве e_indent. Макросы Е1_* суть индексы в этом массиве.
Макросы, следующие за ка'ждым определением Е1_*, суть значения, которые
соответствующий байт может принимать. */
#define EI_MAGO 0 /* Индекс нулевого байта сигнатуры1 */
fdefine ELFMAGO 0x7f /* Значение нулевого байта сигнатуры */
#define EI_MAG1 I /* Индекс первого байта сигнатуры */
#define ELFMAG1 'Е' /* Значение первого байта сигнатуры */
fdefine EI_MAG2 2 /* Индекс второго байта сигнатуры */
#define ELFMAG2 'L' /* Значение второго байта сигнатуры */
#define EI_MAG3 3 /* Индекс третьего байта сигнатуры */
#define ELFMAG3 'F' /* Значение третьего байта сигнатуры */
1 В данном случае — это "магическое число", код, размещаемый
в определенном месте (обычно в начале) файла и подтверждающий, что это
файл данного формата.
/* объединение идентификационных байтов, для сравнения по словам */ #define
ELFMAG "\177ELF" ((define SELFMAG 4
((define EI_CLASS 4 /* Индекс байта, указывающего класс файла */
((define ELFCLASSNONE 0 /* Не определено */
((define ELFCLASS32 1 /* 32-разрядные объекты */
((define ELFCLASS64 2 /* 64-разрядные объекты */ ((define ELFCLASSNUM
3
tdefine EI_DATA 5 /* Индекс байта кодировки данных */
((define ELFDATANONE 0 /* Не определена кодировка данных */
((define ELFDATA2LSB 1 /* Двоичные дополнительные, младший байт первый
*/
#define ELFDATA2MSB 2 /* Двоичные дополнительные, старший байт первый
*/
tdefine ELFDATANUM 3
#define EI_VERSION 6 /* Индекс байта версии файла */ /* Значение должно
быть EV__CURRENT */
#define EIJDSABI 7 /*. идентификатор OS ABI */
tdefine ELFOSABI_SYSV 0 /* UNIX System V ABI */
«define ELFOSABI_HPUX 1 /* HP-UX */
tdefine ELFOSABI_ARM 97 /* ARM */
#define ELFOSABI_STANDALONE 255 /* Самостоятельное (встраиваемое) приложение
* /
#define EI_ABIVERSION 8 /* версия ABI */
#define EI_PAD 9 /* Индекс байтов выравнивания */
/* Допустимые значения для e_type (тип объектного файла). */
#define ETJTONE 0 /* Не указан тип */
#define ET_REL I /* Перемещаемый файл */
#define ET_EXEC 2 /* Исполнимый файл */
#define ET_DYN 3 /* Разделяемьй объектньй файл */
Define ET_CORE 4 /* Образ задачи */
'define ET_NUM 5 /* Количество определенных типов */
e ET_LOPROC OxffOO /* Специфичный для процессора */
ttdefine ET_HIPROC Oxffff /* Специфичный для процессора */ /* Допустимые
значения для e_machine (архитектура). */
ttdefine EM_NONE 0 /* Не указана машина */
ttdefine ЕМ_М32 1 /* AT&T WE 32100 */
ttdefine EM_SPARC 2 /* SUN SPARC */
ttdefine EM_386 3 /* Intel 80386 */
ttdefine EM_68K 4 /* Motorola m68k family */
ttdefine EM_88K 5 /* Motorola m88k family */
ttdefine EM__486 6 /* Intel 80486 */
ttdefine EM_860 7 /* Intel 80860 */
ttdefine EM_MIPS 8 /* MIPS R3000 big-endian */
ttdefine EM_S370 9 /* Amdahl */
ttdefine EM_MIPS_RS4_BE 10 /* MIPS R4000 big-endian */
ttdefine EM RS6000 11 /* RS6000 */
#define EM_PARISC 15 ttdefine EM_nCUBE 16 Idefine EM VPP500 17
/* HPPA */
/* nCUBE */
/* Fujitsu VPP500 */
ttdefine EM_SPARC32PLUS 18 /* Sun's "vSplus" */ ttdefine EM_960
19 /* Intel 80960 */ ttdefine EM PPC 20 /*. PowerPC */
ttdefine ttdefine ttdefine ttdefine ttdefine ttdefine ttdefine ttdefine
ttdefine ttdefine ttdefine ttdefine ttdefine ttdefine ttdefine
EM_V800 36 /* NEC V800 series */ EM_FR20 37 /* Fujitsu FR20 */ EM_RH32
38 /* TRW RH32 */ EM_MMA 39 /* Fujitsu MMA */ EM^ARM 40 /* ARM */ EM_FAKE_ALPHA
41 /* Digital Alpha J
EM_SH 42 EM_SPARCV9 43 EMJTRICORE 44 EM_ARC 45 EM_H8_300 46 EM_H8_300H
47 EM_H8S 48 EM_H8_500 49 EM IA 64 50
/* Hitachi SH */ /* SPARC v9 64-bit */ /* Siemens Tricore */ /* Argonaut
RISC Core */ /* Hitachi H8/300 */ /* Hitachi H8/300H */ /* Hitachi H8S
*/ /* Hitachi H8/500 */ /* Intel Merced */
«define EM_MIPS_X 51 /*
Stanford MIPS-X */
•define EM^COLDFIRE 52 /* Motorola Coldfire */
«define EM_68HC12 53 /* Motorola M68HC12 */ ((define EM_NUM 54
/* Если необходимо вьщелить неофициальное значение для ЕМ_*, пожалуйста,
выделяйте большие случайные числа (0x8523, Oxa7f2, etc.), чтобы уменьшить
вероятность пересечения с официальными или не-GNU неофициальными значениями.
*/
((define EM_ALPHA 0x9026
/* Допустимые значения для e_version (версия). */
Idefine EV_NONE 0 /* Недопустимая версия ELF */ #define EV_CURRENT I /*
Текущая версия */ (tdefine EV_NUM 2
/* Элемент таблицы символов. */
typedef struct f
Elf32_Word st_name; /* Имя символа (индекс в таблице строк) */
Elf32_Addr st_value; /* Значение символа */
Elf32_Word st_size; /* Размер символа */
unsigned char st_info; /* Тип и привязка символа */
unsigned char st_other; /* Значение не определено, 0 */
Elf32_Section st_shndx; /* Индекс секции */ ) Elf32_Sym;
'* Секция syminfo, если присутствует, содержит дополнительную информацию
о каждом динамическом символе. */
typedef struct I
Elf32_Half si_boundto;/* Прямая привязка, символ, к которому привязан
*/ Elf32_Half si_flags; /* Флаги символа */
> Elf32 Syminfo;
/*
Допустимые значения для si boundto. */
#define SYMINFO_BT_SELF Oxffff /* tdefine SYMINFO_BT_PARENT Oxfffe /*
ttdefine SYMINFO_BT_LOWRESERVE OxffOO /*
/* Возможные битовые маски для si_flags #define SYMINFO_FLG_DIRECT 0x0001
/*
tfdefine SYMINFO_FLG_PASSTHRU 0x0002 /* тора */
tfdefine SYMINFO_FLG_COPY 0x0004 /* tdefine SYMINFO_FLG_LAZYLOAD 0x0008
/*
/* Значения версии Syminfo. */ #define SYMINFO_NONE 0 ttdefine SYMINFO_CURRENT
1 #define SYMINFO NUM 2
Символ привязан к себе */ Символ привязан к родителю */ Начало зарезервированных
записей */
Прямо привязываемый символ *•/ Промежуточный символ для трансля-
Символ предназначен для перемещения копированием */ Символ привязан к
объекту с отложенной загрузкой */
/* Как извлекать информацию из и включать ее в поле st_info. */
•
#define ELF32_ST_BIND(val) (((unsigned char) (val)) » 4) tfdefine ELF32_ST_TYPE(val)
((val) & Oxf)
ttdefine ELF32_ST_INFO(bind, type) (((bind) « 4) + ((type) & Oxf))
/* Допустимые значения для подполя STJ3IND поля st_info (привязка символов).
*/
#define STB_LOCAL О ttdefine STB_GLOBAL 1 tdefine STB_WEAK 2 ttdefine
STB_NUM 3 #define STB_LOOS 10 #define STB HIOS 12
/* Локальный символ */
/* Глобальный символ */
/* Слабый символ */
/* Кол-во определенных типов. */
/* Начало ОС-зависимых значений */ _ /* Конец ОС-зависимых значений */
#define STB_LOPROC 13 /* Начало процессорно-зависимых значений */ tdefine
STB_HIPROC 15 /* Конец процессорно-зависимых значений */
/* Допустимые значения для подполя ST TYPE поля st info (тип символа).
*/
#define STT_NOTYPE 0 #define STT_OBJECT 1 #define STT FUNC 2
He указан */
Символ — объект данных */
Символ — объект кода */
STT_SECTION 3 /* Символ связан с секцией */
4define STT_FILS 4 /* Имя символа — имя файла */
*define ^тт NUM ^ /* Кол-во определенных типов */
»define STT LOOS 1^ /* Начало ОС-зависимых значений */
«define STT_HIOS 12 /* Конец ОС-зависимых значений */
*define STT_LOPROC 13 /* Начало процессорно-зависимых значений */
«define STT_HIPROC 15 /* Конец процессорно-зависимых значений */
/* Индексы таблицы символов размещены в группах и цепочках хэша в секции
кэш-таблицы символов. Это специальное значение индекса указывает на конец
цепочки, и означает, что в этой группе более нет символов. */
((define STNJJNDEF 0 /* Конец таблицы. */
/* Элемент таблицы перемещений без добавочного значения (в секциях типа
SHT_REL). */
typedef struct (
Elf32_Addr r_offset; /* Адрес */
Elf32_Word r_info; /* Тип перемещения и индекс символа */ } Elf32_Rel;
/* Элемент таблицы перемещений с добавочным значением (в секциях типа
SHT_RELA). */
typedef struct (
Elf32_Addr r_offset; /* Адрес */
Elf32_Word r_info; /* Тип перемещения и индекс символа */
Elf32_Sword r_addend; /* Добавочное значение */ ) Elf32_Rela;
'•* Как извлекать информацию из и включать ее в поле r_info. */
#define ELF32_R_SYM(val) ((val) » 8)
Define ELF32_R_TYPE(val) ((val) & Oxff)
#define ELF32_R_INFO(sym, type) (((sym) « 8) + ((type) & Oxff))
/* Типы перемещений для 1386 (формулы взяты из
[docs.sun.com 816-0559-10] - авт.)
А — добавочное значение, используемое при вычислении значения перемещаемого
поля.
В — базовый адрес, начиная с которого разделяемый объект загружается в
память при исполнении [программы]. Обычно разделяемый объект строится
с базовым виртуальным адресом, равным О, но адрес при исполнении иной.
G — смещение записи в глобальной таблице смещений, где адрес перемещаемого
символа находится во время исполнения. GOT — адрес глобальной таблицы
смещений.
L — местоположение (смещение в секции или адрес) записи символа в процедурной
таблице связывания (PLT). PLT перенаправляет вызов функции по настоящему
адресу. Редактор связей создает начальную таблицу, а редактор связей времени
исполнения модифицирует записи во время исполнения.
Р — местоположение (смещение в секции или адрес) перемещаемого элемента
памяти (вычисляется с использованием r_offset).
S — значение символа, индекс которого находится в" элементе таблицы
перемещений. */
#define R_386_NONE 0 /* Не перемещать */
ttdefine R__386_32 I /* Прямое 32-разрядное - S + А */
#define R_386_PC32 2 /* 32-разрядное относительно PC-S+A-PV
^define R_386_GOT32 3 /* 32-разрядный элемент GOT - G + А */
#define R_386_PLT32 4 /* 32-разрядный адрес PLT - L + А - Р */
ttdefine R_386_COPY 5 /* Копировать символ при исполнении */
#define R_386_GLOB_DAT 6 Л Создать запись GOT - S*/
#define R_386_JMP_SLOT 7 /* Создать запись PLT - S */
tfdefine R_386_RELATIVE 8 /* Сдвинуть относительно базы программы -
В + А */
tdefine R_386_GOTOFF 9 /* 32-разрядное смещение GOT - S + А - GOT */ ^define
R_386_GOTPC 10 /*' 32-разрядное смещение GOT относительно
PC - S + А - GOT */ /* Должна быть последняя запись. */ #define R 386
NUM 11
Объектные библиотеки
Крупные программы часто состоят из сотен и тысяч отдельных
модулей. Кроме того, существуют различные пакеты подпрограмм, также состоящие
О большого количества модулей. Один из таких пакетов используется практически
в любой программе на языке высокого уровня — это так называемая стандартная
библиотека. Для решения проблем, возникающих при поддержании порядка в
наборах из большого количества объектных модулей, еше на заре вычислительной
техники были придуманы библиотеки объектных модулей.
Библиотека, как правило, представляет собой последовательный файл, состоящий
из заголовка, за которым последовательно располагаются объектные модули
(рис. 3.11). В заголовке содержится следующая информация.
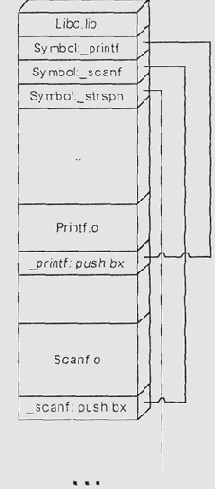
Рис. 3.11. Объектная библиотека
Линкер (рис. 3.12) обычно собирает в программу все объектные
модули, которые были ему заданы в командной строке, даже если на этот
модуль не было ни одной ссылки. С библиотечными модулями он ведет себя
несколько иначе.
Встретив ссылку на глобальный символ, компоновщик ищет определение этого
символа во всех модулях, которые ему были заданы. Если там такого символа
нет, то линкер ищет этот символ в заголовке библиотеки. Если его нет и
там, компоновщик сообщает: "Не определен символ SYMBOL",- и
завершает работу. Некоторые редакторы связей, правда, могут Продолжить
работу и даже собрать загружаемый модуль, но, как правило, таким модулем
пользоваться нельзя, так как в нем содержится ссылка на некорректный адрес.
Если же определение символа в библиотеке есть, компоновщик "вытаскивает"
соответствующий модуль ц дальше работает так, будто этот модуль был задан
ему наравне с остальным^ объектными файлами. Этот процесс повторяется
до тех пор, пока не будут разрешены все глобальные ссылки, в том числе
и те, которые возникли в библиотечных модулях, или пока не будет обнаружен
неопределенный символ. Благодаря такому алгоритму в программу включаются
только те модули из библиотеки, которые нужны.
В системах семейства Unix библиотеки такой структуры называются архивными
библиотеками, чтобы отличить их от разделяемых библиотек, которые
рассматриваются в разд. Динамические
библиотеки и Разделяемые библиотеки.

Рис. 3.12. Блок-схема работы редактора связей
Сборка в момент загрузки
| ...как только они вошли в Бесконечный Лес,
собранный джентельмен стал разбираться на части и принялся выплачивать
арендные деньги. Сначала он отправился к ногозаимодавцам и пришел
туда, где нанял левую ногу; он отдал ее владельцу, и заплатил за аренду,
и запрыгал к хозяину правой ноги; когда он вернул ее и полностью расплатился,
то перевернулся вниз головой и поскакал на руках. А. Тутуола |
Как мы видели в предыдущем разделе, объектные модули и библиотеки содержат
достаточно информации, чтобы собирать программу не только заранее, но
и непосредственно в момент загрузки. Этот способ, безусловно, требует
больших затрат процессорного времени, чем загрузка заранее собранного
кода, но дает и некоторые преимущества.
Главное преимущество состоит в том, что, если мы загружаем несколько программ,
использующих одну и ту же библиотеку, мы можем настроить их на работу
с одной копией кода библиотеки, таким образом, сэкономив память. Разделение
кода привлекательно и с функциональной точки зрения, поэтому сборка в
момент загрузки находит широкое применение в самых разнообразных ситуациях.
Примером такой сборки является широко используемая в Windows всех версий
и OS/2 технология DLL (на самом деле, DLL обеспечивают сборку не только
в момент загрузки, но и после нее — возможность подключить дополнительный
модуль к уже загруженной программе), которая будет более подробно обсуждаться
далее. В качестве других примеров можно привести Novell Netware, OS-9,
VxWorks и т. д. Впрочем, если мы говорим о системах, предназначенных для
использования во встроенных приложениях (той же VxWorks), вопрос о том,
является ли сборка перед прошивкой в ПЗУ сборкой в момент загрузки или
сборкой заранее, носит схоластический характер.
Некоторые системы команд поддерживают динамически пересобираемые программы,
у которых вся настройка модуля вынесена в отдельную таблицу. В этом случае
модуль может быть подключен одновременно к нескольким программам, использовать
одновременно разные копии сегмента данных, и каждая используемая копия
модуля при этом даже не будет подозревать о существовании других. Примером
такой архитектуры является Pascal-система Lilith, разработанная Н. Виртом,
и ее наследники KpoHoc/N9000.
Программные модули в N9000
В этих архитектурах каждый объектный модуль соответствует одному модулю
в смысле языка высокого уровня Oberon (или NIL— N9000 Instrumental Language).
Далее мы будем описывать архитектуру системы N9000, поскольку автор с
ней лучше знаком.
Модуль может иметь не более 256 процедур, не более 256 переменных и ссылаться
не более чем на 256 других модулей. Код модуля является позиционно-независимым.
Данные модуля собраны в отдельный сегмент, и для каждой используемой копии
модуля, т. е. для каждой программы, которая этот модуль использует, создается
своя копия сегмента данных. В начале сегмента содер.
жится таблица переменных. Строки этой таблицы содержат либо значения_
для скалярных переменных, таких как целое число или указатель, либо адреса
в сегменте данных. Кроме того, сегмент данных содержит ссылку на сегмент
кода. Этот сегмент кода содержит в себе таблицу адресов точек входа всех
определенных в нем функций (рис. 3.13).

Рис. 3.13. Модуль N9000
Ссылки на все внешние модули собраны в таблицу, которая
также содержится в сегменте данных. Внешний модуль определяется началом
его сегмента данных
Все ссылки на объекты в данном модуле осуществляются через индекс в соответствующей
таблице. Ссылки на внешние модули имеют вид индекс
модуля:индекс объекта.
Сегмент данных не может содержать никаких статически инициализованных
данных. Вся инициализация производится специальной процедурой, которая
вызывается при каждом новом использовании модуля. Все эти свойства реализованы
в системе команд, поэтому накладные расходы относительно невелики.
Точнее, они невелики по сравнению с Intel 80286, но уже великоваты по
сравнению с i386, а по сравнению с современными RISC-процессорами или
системами типа транспьютера они становятся недопустимыми. Впрочем, в разд.
Разделяемые библиотеки мы увидим,
как подобная структура используется и на "обычных" процессорах.
Видно, что в системе может существовать несколько программ, обращающихся
к одним и тем же модулям и использующих одну и ту же копию кода модуля.
Проблем с абсолютной/относительной загрузкой вообще не возникает. Операционная
система ТС для N9000 была (автор не уверен, существует ли в настоящее
время хотя бы одна работоспособная машина этой архитектуры) основана на
сборке программ в момент загрузки. В системе имелась специальная команда
load — "загрузить все модули, используемые программой, и разместить
для них сегменты данных, но саму программу не запускать". В памяти
могло находиться одновременно несколько программ; при этом модули, используемые
несколькими из них, загружались в одном экземпляре. Это значительно ускоряло
работу. Например, можно было загрузить в память текстовый редактор, и
запуск его занимал бы доли секунды, вместо десятков секунд, которые нужны
для загрузки с жесткого диска фирмы ИЗОТ.
Любопытно, что когда началась реализация системы программирования на языке
С для этой машины, по ряду причин было решено не связываться с динамической
сборкой, а собирать обычные перемещаемые загрузочные модули.
На практике, подобная архитектура более характерна для байт-кодов — пре-компилированных
представлений программы, предназначенных для дальнейшей обработки интерпретатором
— Java Virtual Machine, интерпретатором Smalltalk и т. д., чем для аппаратно
реализованных систем команд. В таких системах команд порой используются
и более экстравагантные решения.
Архитектура AS/400
Система команд AS/400 (сервер баз данных среднего уровня, производимый
IBM) представляет собой машинно-независимый байт-код. При загрузке программы
этот байт-код компилируется в бинарный код "реального" процессора,
подобно тому, как это делается в большинстве современных реализаций Java
Virtual Machine. Точнее, наоборот, успех AS/400 был одним из важных факторов,
которые подвигли фирму Sun на разработку Java, поэтому правильнее говорить,
что современные JVM основаны на том же принципе компиляции при загрузке,
что и AS/400.
Это решение обеспечивает невысокую стоимость аппаратуры (современные AS/400
основаны на микропроцессорах архитектуры Power PC. Их более высокая по
сравнению с машинами, основанными на процессорах х86, цена обусловлена
более производительными системной шиной и периферией), высокую производительность
и возможность заменять архитектуру "реального" процессора без
перекомпиляции пользовательского программного обеспечения. За время выпуска
машин этой серии такая замена происходила дважды.
С другой стороны, отсутствие необходимости думать о том, как та или иная
возможность может быть реализована аппаратно, позволила принимать весыуа
авангардистские решения, на которые не решался никто из разработчиков
аппаратно реализованных CISC-архитектур, таких как VAX, Eclipse и даже
апофеоза CISC, Intel 432.
AS/400 имеет единое адресное пространство в том смысле, что адресуемыми
объектами являются не только сегменты кода и скалярных данных, но и объекты
реляционной СУБД, такие, как таблицы, индексы, курсоры и т. д.
Фактически, адресации подлежит вся память системы как оперативная, так
и дисковая. Адрес имеет два представления: его сегментная часть может
хранить имя адресуемого объекта (в контексте этой главы это можно уподобить
неразрешенной внешней ссылке) или собственно адрес, 64-битовое бинарное
значение. Перед тем, как обратиться к объекту, адрес-имя надо преобразовать
в бинарный формат, для чего существуют специальные команды [redbooks.ibm.com
sg242222.pdf].
Механизм этого преобразования выполняет работу и файловой системы, и редактора
связей, в том смысле, что и файловый доступ, и сборка программы содержат
важную фазу преобразования имен (соответственно, имен файлов и имен внешних
символов) в адреса, по которым можно осуществлять доступ.
Сборка при загрузке замедляет процесс загрузки программы (впрочем, для
современных процессоров это замедление вряд ли имеет большое значение),
но упрощает, с одной стороны, разделение кода, а с другой стороны — разработку
программ. Действительно, из классического цикла внесения изменения в программу:
редактирование текста — перекомпиляция — пересборка — перезагрузка (программы,
не обязательно всей системы) выпадает целая фаза. В случае большой программы
это может быть длительная фаза. В случае Novell Netware решающим оказывается
первое преимущество (рис. 3.14), в случае систем реального времени одинаково
важны оба.
В большинстве современных ОС, в действительности, сборка в момент загрузки
происходит не из объектных модулей, а из предварительно собранных разделяемых
библиотек. Такие библиотеки отличаются от обсуждавшихся в разд.
Объектные библиотеки, во-первых,
тем, что из них невозможно извлечь отдельный модуль: все межмодульные
ссылки внутри такой библиотеки разрешены, и ее необходимо всегда загружать
как целое; и, во-вторых, тем, что список символов, экспортируемых такой
библиотекой, не является объединением списков экспорта составляющих ее
объектных модулей. При сборке такой библиотеки необходимо указать, какие
из символов будут экспортироваться. Некоторые редакторы связей позволяют
на этом этапе создавать дополнительные символы.

Рис. 3.14. Фрагмент структуры взаимозависимостей между NLM (Netware Loadable Module) сервера Netware 4.11
Динамические библиотеки
В Windows и OS/2 используется именно такой способ загрузки. Исполняемый
модуль в этих системах содержит ссылки на другие модули, называемые DLL
(Dynamically Loadable Library, динамически загружаемая библиотека). Фактически,
каждый модуль в этих системах обязан содержать хотя бы одну ссылку на
DLL, потому что интерфейс к системным вызовам в этих ОС также реализован
в виде DLL.
DLL представляют собой библиотеки в том смысле, что обычно они собираются
из нескольких объектных модулей. Но, в отличие от архивных библиотек,
из DLL нельзя извлечь отдельный модуль, при присоединении библиотеки к
программе она присоединяется и загружается целиком.
Главное достоинство DLL состоит в том, что модуль (как основной, так и
библиотечный), по собственному желанию, может выбирать различные библиотеки,
подгружая их уже после своей собственной загрузки. При этом нет даже строгого
ограничения на совместимость этих библиотек по вызовам (две библиотеки
совместимы по вызовам, если они имеют одинаковые точки входа с одинаковой
семантикой): загрузчик предоставляет возможность просмотреть список глобальных
символов, определенных в библиотеке и получить указатель на каждый символ,
обратившись к нему по имени' (впрочем, количество и типы параметров или
тип переменной, а тем более их семантику, загрузчик не сообщает — эту
информацию надо получать из других источников, например из списка зарегистрированных
в системе объектов СОМ).
Особенно удобна возможность вызывать любую функцию по имени при обращении
к внешним модулям из интерпретируемых языков. В примере 3.9 для подключения
внешних библиотек (в данном случае это стандартная библиотека RexxUtil
и библиотека доступа к сетевым сервисам rxSock) применяются две процедуры:
сначала RxFuncAdd с тремя параметрами: имя символа
REXX, который будет использоваться для обращения к вызываемой функции,
имя DLL и имя символа в этой DLL, а потом специальная функция, предоставляемая
модулем (sysLoadFunc и sockLoadFunc
соответственно), которая регистрирует в интерпретаторе REXX остальные
функции модуля.
Пример 3.9. Пример использования динамической библиотеки (здесь — REXX | I Socket) в интерпретируемом языке
/**************************************************
ПРОСТОЙ HTTP клиент на REXX
Dmitry Maximovich 2:5030/544.60 aka maxim@pabl.ru
**************************************************/
PARSE VALUE ARC (1) WITH Al A2
IF Al = " THEN DO
SAY 'USAGE: wwwget hostname[/path] [port]' EXIT
END
ELSE
DO
PARSE VALUE Al WITH B1'/'B2
sServer = Bl
IF B2 = '' THEM
DO
sRequest = 'GET / HTTP 1.0'|I"ODOAODOA"x
SAY''Requesting /' END ELSE DO
sRequest = 'GET /'|IB2I|' HTTP 1.0'|I"ODOAODOA"x
SAY 'Requesting /'||B2
END
END
IF A2 <> " THEN
DO
nPortNumber = A2
END
-ELSE
DO
nPortNumber =80
END
/* Загрузить REXX Socket Library если еще не загружена*/
IF RxFuncQuery("SockLoadFuncs") THEN
DO
re = RxFuncAddf"SockLoadFuncs","rxSock","SockLoadFuncs")
re = SockLoadFuncs ()
END
IF RxFuncQuery("SysLoadFuncs") THEN
DO
re = RxFuncAdd( "SysLoadFuncs","RexxUtil","SysLoadFuncs")
re = SysLoadFuncs()
END
rc=SockGetHostByName(sServer,"host.")
IF rс <> 1 THEN
DO
SAY 'CANNOT RESOLVE HOSTNAME TO ADDRESS: 'sServer EXIT -1 END
SAY 'Trying server : 'host .name1 , address: 'host .addr' , port: 'nPortNumber
socket = SockSocket('AF_INET','SOCK_STREAM',0) IF socket < 0 THEN DO
SAY 'UNABLE TO CREATE A SOCKET' EXIT -1
END
address.familу = 'AF_INET' address.port = nPortNumber address.addr = host.addr
rc = SockConnect(socket,'address.')
IF re < 0 THEN
DO
SAY 'UNABLE TO CONNECT TO SERVER:'address.addr
SIGNAL DO
END
re = SockSend(socket, sRequest)
SAY 'REQUEST'***************************************************'
Resp = ''
DO FOREVER
re = SockRecv(socket,"sReceive",256)
IF re <= 0 THEN LEAVE
Resp = Resp || sReceive END
SAY
/* CR -> CRLF */
nStart = 1
nStop = pos(X2C("OA"), Resp)
do while nStop > 0
SAY SUBSTR(Resp,nStart,nStop-nStart)
nStart = nStop + 1
nStop = pos(X2C("OA"), Resp, nStart)
end
DO:
rc = SockShutDown(socket,2)
rc = SockClose(socket)
При сборке DLL из нескольких объектных модулей программист должен предоставить
DEF-файл (пример 3.10). В этом файле содержится перечисление символов,
экспортируемых библиотекой (в отличие от обычных, "архивных"
библиотек, набор этих символов не обязательно равен объединению наборов
экспортных символов всех включенных в библиотеку объектов), а также некоторые
другие параметры. Например, можно указать, что DLL имеет функции инициализации
и терминации. Эти функции могут запускаться как при первой загрузке библиотеки
(INITGLOBAL), так и при подключении библиотеки
очередной программой (INITINSTANCE). Можно также
управлять разделением сегмента данных DLL — применять общий сегмент данных
для всех программ, использующих библиотеку, или создавать свою копию для
каждой программы.
Пример 3.10. DEF-файл из примеров кода VisualAge
C++ V3.0
LIBRARY REXXUTIL INITINSTANCE LONGNAMES
PROTMODE
DESCRIPTION 'REXXUTIL Utilities - (c) Copyright IBM Corporation 1991'
DATA MULTIPLE NONSHARED STACKSIZE 32768
EXPORTS
SYSCLS = SysCls @1 SYSCURPOS = SysCurPos @2 SYSCURSTATE = SysCurState
@3 SYSDRIVEINFO = SysDrivelnfo @4
SYSDRIVEMAP = SysDriveMap @5
SYSDROPF0NCS = SysDropFuncs @6
SYSFILEDELETE = SysFileDelete @7
SYSFILESEARCH = SysFileSearch @8
SYSFILETREE - SysFileTree @9
SYSGETMESSAGE = SysGetMessage 010
SYSINI = Syslni 011
SYSLOADFUNCS = SysLoadFuncs @12
SYSMKDIR = SysMkDir @13
SYSOS2VER = SysOS2Ver 014
SYSRMDIR = SysRmDir @15
SYSSEARCHPATH = SysSearchPath @16
SYSSLEEP = SysSleep @17
SYSTEMPFILENAME = SysTempFileName @18
SYSTEXTSCREENREAD = SysTextScreenRead @19
SYSTEXTSCREENSIZE = SysTextScreenSize La20
SYSGETEA = SysGetEA @21
SYSPUTEA = SysPutEA @22
SYSWAITNAMEDPIPE = SysWaitNamedPipe @23
DLL являются удобным средством разделения кода и создания отдельно загружаемых
программных модулей, но их использование сопряжено с определенной проблемой,
которая будет подробнее объясняться в разд.
Разделяемые библиотеки. Забегая вперед, скажем, что концепция разделяемых
DLL наиболее естественна в системах, где веб задачи используют единое
адресное пространство — но при этом ошибка в любой из программ может привести
к порче данных или кода другой задачи. Стандартный же способ борьбы с
этой проблемой — выделение каждому процессу своего адресного пространства
— значительно усложняет разделение кода.
Другая проблема, обусловленная широким использованием разделяемого кода,
состоит в слежении за версией этого кода. Действительно, представим себе
жизненную ситуацию: в системе одновременно загружены тридцать программ,
использующие библиотеку LIBC.DLL. При этом десять из них разрабатывались
и тестировались с версией 1.0 этой библиотеки, пять — с версией 1.5 и
пятнадцать — с версией 1.5а. Понятно, что рассчитывать на устойчивую работу
всех тридцати программ можно только при условии, что все три версии библиотеки
полностью совместимы снизу вверх не только по набору вызовов и их параметров,
но и по точной семантике каждого из этих вызовов. Последнее требование
иногда формулируют как bug-for-bug compatibility
(корректно перевести это словосочетание можно так: полная
совместимость не только по спецификациям, но и по отклонениям от них).
Казалось бы, исправление ошибок должно лишь улучшать работу программ,
использующих исправленный код. На практике же бывают ситуации, когда код
основной программы содержит собственные обходные пути, компенсирующие
ошибки в библиотеке. Эти обходы могут быть как внесены сознательно (когда
поставщик библиотеки исправит, еще неизвестно, а программа нужна сейчас),
так и получиться сами собой (арифметический знак, перепутанный четное
число раз и т. д.). В этих случаях исправление ошибки может привести к
труднопредсказуемым последствиям. Нельзя также забывать и о возможности
внесения новых ошибок при исправлении старых, поэтому при разработке и
эксплуатации сложных программных систем, необходимо тщательно следить
за тем, что именно и где изменилось, а не просто фиксировать ошибки.
Требование "совместимости с точностью до ошибок" — это лишь
полемически заостренная формулировка требования контролируемости поведения
кода. Из вышеприведенных соображений понятно, что нарушения такой контролируемости
представляют собой проблему, которая, не будучи так или иначе разрешена,
может серьезно усложнить работу администраторов системы и приложений.
Разделяемый код в системах семейства
Windows
Катастрофические масштабы эта проблема принимает в системах семейства
Windows, где принято помещать в дистрибутивы прикладных программ все потенциально
разделяемые модули, которые этой программе могут потребоваться — среда
исполнения компилятора и т. д. При этом каждое приложение считает своим
долгом поместить свои разделяемые модули в C:\WINDOWS\SYSTEM32 (в Windows
NT/2000/XP это заодно приводит к тому, что установка самой безобидной
утилиты требует администраторских привилегий). Средств же проследить за
тем, кто, какую версию, чего, куда и зачем положил, практически не предоставляется.
В лучшем случае установочная программа спрашивает: "Тут вот у вас
что-то уже лежит, перезаписать?". Стандартный деинсталлятор содержит
список DLL, которые принадлежат данному приложению, и осознает тот факт,
что эти же DLL используются кем-то еще, но не предоставляет (и, по-видимому,
не пытается собрать) информации о том, кем именно они используются. Наличие
реестра объектов СОМ не решает проблемы, потому что большая часть приносимого
каждым приложением "разделяемого" кода (кавычки стоят потому,
что значительная часть этого кода никому другому, кроме принесшего его
приложения, не нужна) не является сервером СОМ.
В результате, когда, например, после установки MS Project 2000 перестает
работать MS Office 2000 [MSkb RU270125], это никого не удивляет, а конфликты
между приложениями различных разработчиков или разных "поколений"
считаются неизбежными. Установить же в одной системе и использовать хотя
бы попеременно две различные версии одного продукта просто невозможно
— однако, когда каждая версия продукта использует собственный формат данных,
а конверсия между ними неидеальна, это часто оказывается желательно.
Разработчики же и тестеры, которым надо обеспечить совместимость с различными
версиями существующих приложений, при этом просто оказываются в безвыходной
ситуации. Неслучайно поставщики VmWare (системы виртуальных машин для
х8б) как одно из главных достоинств своей системы рекламируют возможность
держать несколько копий Windows одновременно загруженными на одной машине.
Привлекательный путь решения этой проблемы — давать каждому приложе-нию
возможность указывать, какие именно DLL ему нужны и где их искать, и позволять
одновременно загружать одноименные DLL с разной семантикой — на самом
деле вовсе не прост как с точки зрения реализации, так и с точки зрения
управления системой. Системы с виртуальной памятью предлагают некоторые
подходы к реализации этого пути, но это будет обсуждаться в разд. Разделяемые
библиотеки.
Загрузка самой ОС
| — Опять себя за волосы дергал ("Тот самый Мюнхаузен"), Г. Горин |
При загрузке самой ОС возникает специфическая проблема: в пустой машине,
скорее всего, нет программы, которая могла бы это сделать.
В системах, в которых программа находится в ПЗУ (или другой энергонезависимой
памяти) этой проблемы не существует: при включении питания программа в
памяти уже есть и сразу начинает испблняться. При включении питания или
аппаратном сбросе процессор исполняет команду, находящуюся по определенному
адресу, например, OxFFFFFFFA. Если там находится ПЗУ, а в нем записана
программа, она и начинает исполняться.
При разработке программ для встраиваемых приложений часто используются
внутрисхемные имитаторы ПЗУ, доступные целевой системе как ПЗУ, а системе
разработчика — как ОЗУ или специальное внешнее устройство.
Компьютеры общего назначения также не могут обойтись без ПЗУ. Программа,
записанная в нем, называется загрузочным монитором.
Стартовая точка этой программы должна находиться как раз по тому адресу,
по которому процессор передает управление в момент включения питания.
Эта программа производит первичную инициализацию процессора, тестирование
памяти и обязательного периферийного оборудования, и, наконец, начинает
загрузку системы. В компьютерах, совместимых с IBM PC, загрузочный монитор
известен как BIOS.
На многих системах в ПЗУ бывает прошито нечто большее, чем первичный загрузчик.
Это может быть целая контрольно-диагностическая система, называемая
консольным монитором. Такая система есть на всех машинах линии
PDP-11/VAX и на VME-системах, рассчитанных на OS-9 или VxWorks. Такой
монитор позволяет вам просматривать содержимое памяти по заданному адресу,
записывать туда данные, запускать какую-то область памяти как программу
и многое другое. Он же позволяет выбирать устройство, с которого будет
производиться дальнейшая загрузка. В PDP-11/VAX на таком мониторе можно
писать программы, почти с таким же успехом, как на ассемблере. Нужно только
уметь считать в уме в восьмеричной системе счисления. иа машинах фирмы
Sun в качестве консольного монитора используется интерпретатор языка Forth.
На ранних моделях IBM PC в ПЗУ был прошит щтерпретатор BASIC. Именно поэтому
клоны IBM PC имеют огромное ко-чичество плохо используемого адресного
пространства выше сегмента ОхСООО. Вы можете убедиться в том, что BASIC
там должен быть, вызвав из программы прерывание 0x60. Вы получите на мониторе
сообщение вроде: NO
ROM BASIC, PRESS ANY KEY TO REBOOT. Вообщеговоря, этот BASIC не
является консольным монитором в строгом смысле этого слова, так как получает
управление не перед загрузкой, а лишь после того, как загрузка со всех
устройств завершилась неудачей.
После запуска консольного монитора и инициализации системы вы можете приказать
системе начать собственно загрузку ОС. На IBM PC такое приказание отдается
автоматически, и часто загрузка производится вовсе не с того устройства,
с которого хотелось бы. На этом и основан жизненный цикл загрузочных вирусов.
Чтобы загрузочный монитор смог что бы то ни было загрузить, он должен
уметь проинициализировать устройство, с которого предполагается загрузка,
и считать с него загружаемый код. Поэтому загрузочный монитор обязан содержать
модуль, способный управлять загрузочным устройством. Например, типичный
BIOS PC-совместимого компьютера содержит модули управления гибким диском
и жёстким диском с интерфейсом Seagate 506 (в современных компьютерах
это обычно интерфейс EIDE, отличающийся от Seagate 506 конструктивом,
но программно совместимый с ним сверху вниз).
Кроме того, конструктивы многих систем допускают установку ПЗУ на платах
контроллеров дополнительных устройств. Это ПЗУ должно содержать программный
модуль, способный проинициализировать устройство и произвести загрузку
с него (рис. 3.15).

Рис. 3.15. Системное ПЗУ и BIOS дискового контроллера
Как правило, сервисы загрузочного монитора доступны загружаемой системе.
Так, модуль управления дисками BIOS PC-совместимых компьютеров предоставляет
функции считывания и записи отдельных секторов диска Доступ к функциям
ПЗУ позволяет значительно сократить код первичного загрузчика ОС, и, нередко,
сделать его независимым от устройства.
Проще всего происходит загрузка с различных последовательных устройств
— лент, перфолент, магнитофонов, перфокарточных считывателей и т. д. Загрузочный
монитор считывает в память все, что можно считать с заданного устройства
и передает управление на начало той информации которую прочитал.
В современных системах такая загрузка практически не используется. В них
загрузка происходит с устройств с произвольным доступом, как правило —
с дисков. При этом обычно в память считывается нулевой сектор нулевой
дорожки диска. Содержимое этого сектора называют первичным
загрузчиком. В IBM PC этот загрузчик называют загрузочным
сектором, или boot-сектором.
Как правило, первичный загрузчик, пользуясь сервисами загрузочного монитора,
ищет на диске начало файловой системы своей родной ОС, находит в этой
файловой системе файл с определенным именем, считывает его в память и
передает этому файлу управление. В простейшем случае такой файл и является
ядром операционной системы.
Размер первичного загрузчика ограничен чаще всего размером сектора на
диске, т. е. 512 байтами. Если файловая система имеет сложную структуру,
иногда первичному загрузчику приходится считывать вторичный,
размер которого может быть намного больше. Из-за большего размера этот
загрузчик намного умнее и в состоянии разобраться в структурах файловой
системы. В некоторых случаях используются и третичные загрузчики.
Это последовательное исполнение втягивающих друг друга загрузчиков возрастающей
сложности называется бутстрапом (bootstrap),
что можно перевести как "втягивание [себя] за шнурки от ботинок".
Большую практическую роль играет еще один способ загрузки — загрузка
по сети. Она происходит аналогично загрузке с диска: ПЗУ, установленное
на сетевой карте, посылает в сеть пакет стандартного содержания, который
содержит запрос к серверу удаленной загрузки. Этот сервер передает по
сети вторичный загрузчик и т. д. Такая технология незаменима при загрузке
бездисковых рабочих станций. Централизованное размещение загрузочных образов
рабочих станций на сервере упрощает управление ими, защищает настройки
ОС от случайных и злонамеренных модификаций и существенно удешевляет эксплуатацию
больших парков настольных компьютеров, поэтому по сети нередко загружаются
и машины, имеющие жесткий диск.
Проще всего происходит загрузка систем, ядро которых вместе со всеми дополнительными
модулями (драйверами устройств, файловых систем и др.)
Собрано в единый загрузочный модуль. Например, в системах семейства Unix,
ядро так и называется /unix (в FreeBSD - /vmunix, в Linux -/vnilinux,
пли, и случае упакованного ядра, /vmlinuz).
При переконфигурации системы, добавлении или удалении драйверов и других
модулей необходима пересборка ядра, которая может производиться либо стандартным
системным редактором связей, либо специальными утилитами генерации
системы. Для такой пересборки в поставку системы должны входить
либо исходные тексты (как у Linux и BSD), либо объектные модули ядра.
Сборка ядра из объектных модулей на современных системах занимает не более
нескольких минут. Полная перекомпиляция ядра из исходных текстов, конечно,
продолжается существенно дольше.
На случай, если системный администратор ошибется и соберет неработоспособное
ядро, вторичный загрузчик таких систем часто предоставляет возможность
выбрать файл, который следует загрузить. Ядро таких систем обычно не использует
никаких конфигурационных файлов — все настройки также задаются при генерации.
Большинство современных ОС используют более сложную форму загрузки, при
которой дополнительные модули подгружаются уже после старта самого ядра.
В терминах предыдущих разделов это называется "сборка в момент загрузки".
Список модулей, которые необходимо загрузить, а также параметры настройки
ядра, собраны в специальном файле или нескольких файлах. У DOS и OS/2
этот файл называется CONFIG.SYS, у Win32-cncreM -реестром (registry).
Сложность при таком способе загрузки состоит в том, что ядро, еще полностью
не проишщиализовавшись, уже должно быть способно работать с файловой системой,
находить в ней файлы и считывать их в память.
Особенно сложен этот способ тогда, когда драйверы загрузочного диска и
загрузочной файловой системы сами являются подгружаемыми модулями. Обычно
при этом ядро пользуется функциями работы с файловой системой, предоставляемыми
вторичным (или третичным, в общем, последним по порядку) загрузчиком,
до тех пор, пока не проинициализирует собственные модули. Вторичный загрузчик
обязан уметь читать загрузочные файлы, иначе он не смог бы найти ядро.
Если поставщики ОС не удосужились написать соответствующий вторичный загрузчик,
а предоставили только драйвер файловой системы, ОС сможет работать с такой
файловой системой, но не сможет из нее загружаться.
Некоторые системы, например DOS, могут грузиться только с устройств, поддерживаемых
BIOS, и только из одного типа файловой системы — FAT, Драйвер которой
скомпонован с ядром. Любопытное развитие этой идеи представляет Linux,
модули которого могут присоединяться к ядру как статически, так и динамически.
Динамически могут подгружаться любые модули, кроме драйверов загрузочного
диска и загрузочной ФС.
Преимущества, которые дает динамически собираемое в момент загрузки ядро,
не так уж велики по сравнению с системами, в которых ядро собирается статически.
Впрочем, ряд современных систем (Solaris, Linux, Netware) идут в этом
направлении дальше и позволяют подгружать модули уже после загрузки и
даже выгружать их. Такая архитектура предъявляет определенные требования
к интерфейсу модуля ядра (он должен уметь не только инициализировать сам
себя и, если это необходимо, управляемое им устройство, н0 и корректно
освобождать все занятые им ресурсы при выгрузке), но дает значительные
преимущества.
Во-первых, это допускает подгрузку модулей по запросу. При этом подсистемы,
нужные только иногда, могут не загрузиться вообще. Даже те модули, которые
нужны всегда, могут проинициализироваться, только когда станут нужны,
уменьшив тем самым время от начала загрузки до старта некоторых сервисов.
Второе, пожалуй даже более важное для системного администратора, преимущество
состоит в возможности реконфигурировать систему без перезагрузки, что
особенно полезно для систем коллективного пользования. И, наконец, возможность
выгрузки модулей ядра иногда (но не всегда, а лишь если поломка не мешает
драйверу корректно освободить ресурсы) позволяет корректировать работу
отдельных подсистем — опять-таки без перезагрузки всей ОС и пользовательских
приложений.
Оказавшись в памяти и, так или иначе, подтянув все необходимые дополнительные
модули, ядро запускает их подпрограммы инициализации. При динамической
подгрузке инициализация модулей часто происходит по мере их загрузки.
Обычно инициализация ядра завершается тем, что оно загружает определенную
программу, которая продолжает инициализацию — уже не ядра, но системы
в целом.
Так, системы семейства UNIX имеют специальную инициализационную программу,
которая так и называется — init. Эта программа
запускает различные процессы-демоны, например cron
— программу, которая умеет запускать другие заданные ей программы в заданные
моменты времени, различные сетевые сервисы, программы, которые ждут ввода
с терминальных устройств (getty), и т. д. Набор запускаемых программ задается
в файле /etc/inittab (в разных версиях системы этот файл может иметь разные
имена, /etc/inittab используется в System V). Администратор системы может
редактировать этот файл и устанавливать те сервисы, которые в данный момент
нужны, избавляться от тех, которые не требуются, и т. д.
Программа init остается запущенной все время
работы системы. Она, как правило, следит за дальнейшей судьбой запущенных
ею процессов. В зависимости от заданных в файле /etc/inittab параметров,
она может либо перезапускать процесс после его завершения, либо не делать
этого.
Аналогичный инициализационный сервис в той или иной форме предоставляют
все современные операционные системы.
Загрузка Sun Solaris
Полный цикл загрузки Solaris (версия Unix System V Release 4, поставляющаяся
фирмой Sun) на компьютерах х86 происходит в шесть этапов. Первые три этапа
стандартны для всех ОС, работающих на IBM PC-совместимой технике. При
включении компьютера запускается прошитый в ПЗУ BIOS. Он проводит тестирование
процессора и памяти и инициализацию машины. В процессе инициализации BIOS
устанавливает обработчик прерывания int I3h. Этот обработчик умеет считывать
и записывать отдельные секторы жестких и гибких дисков и производить некоторые
другие операции над дисковыми устройствами. Первичные загрузчики ОС обычно
пользуются этим сервисом. Некоторые ОС, например MS/DR DOS, используют
этот сервис не только при загрузке, но и при работе, и, благодаря этому,
могут не иметь собственного модуля управления дисками.
Если загрузка происходит с жесткого диска, BIOS загружает в память и запускает
нулевой сектор нулевой дорожки диска. Этот сектор обычно содержит не первичный
загрузчик операционной системы, a MBR (Master Boot Record — главная загрузочная
запись). Эта программа обеспечивает разбиение физического жесткого диска
на несколько логических разделов (partition) и возможность попеременной
загрузки различных ОС, установленных в этих разделах (рис. 3.16).
Рис. 3.16. Master Boot Record и таблица разделов
Разбиение физического диска на логические программа MBR
осуществляет на основе содержащейся в ее теле таблицы разделов (partition
table), которая содержит границы и типы разделов. MBR перехватывает прерывание
int 13^ и транслирует обращения к дисковой подсистеме так, что обращения
к логическому диску N преобразуются в обращения к N-ному разделу физического
диска
Один из разделов диска должен быть помечен как активный или загрузочный.
MBR загружает начальный сектор этого раздела — обычно это и есть первичный
загру3. чик ОС. Многие реализации MBR, в том числе и поставляемая с Solaris,
могут предоставлять пользователю выбор раздела, с которого следует начинать
загрузку Выбор обычно предоставляется в форме паузы, в течение которой
пользователь может нажать какую-то клавишу или комбинацию клавиш. Если
ничего не будет нажато, начнется загрузка с текущего активного раздела.
Так или иначе, но загрузочный сектор — по совместительству, первичный
загрузчик Solaris оказывается в памяти и начинает исполняться. Исполнение
его состоит в том, что он загружает — нет, еще не ядро, а специальную
программу, называемую DCU (Device Configuration Utility, утилита конфигурации
устройств). Основное назначение этой программы — имитация сервисов консольного
монитора компьютеров фирмы Sun на основе процессоров SPARC.
DCU производит идентификацию установленного в машине оборудования. Пользователь
может вмешаться в этот процесс и, например, указать системе, что такого-то
устройства в конфигурации нет, даже если физически оно и присутствует,
или установить драйверы для нового типа устройств. Драйверы, используемые
DCU, отличаются от драйверов, используемых самим Solaris, называются они
BEF (Boot Executable File), и начинают исполнение, как и сама DCU, в.реальном
режиме процессора х86. .
Найдя все необходимое оборудование, DCU запускает вторичный загрузчик
Solaris. Логический диск, выделенный Solaris, имеет внутреннюю структуру
и также разбит на несколько разделов (рис. 3.17). Чтобы не путать эти
разделы с разделами, создаваемыми MBR, их называют слайсами (slice). Загрузочный
диск Solaris должен иметь минимум два слайса — Root (корневая файловая
система) и Boot, в котором и размещаются вторичный загрузчик и DCU.
Вторичный загрузчик, пользуясь BEF-модулем загрузочного диска для доступа
к этому диску, считывает таблицу слайсов и находит корневую файловую систему.
В этой файловой системе он выбирает файл /kernel/unix, который и является
ядром Solaris. В действительности, вторичный загрузчик исполняет командный
файл, в котором могут присутствовать условные операторы, и, в зависимости
от тех или иных условий, в качестве ядра могут быть использованы различные
файлы, /kernel/unix используется по умолчанию.
Кроме того, пользователю предоставляется пауза (по умолчанию 5 секунд),
в течение которой он может прервать загрузку по умолчанию и приказать
загрузить какой-то другой файл, или тот же файл, но с другими параметрами.
Будучи так или иначе загружено, ядро, пользуясь сервисами вторичного загрузчика,
считывает файл /etc/system, в котором указаны параметры настройки системы.
Затем, пользуясь информацией, предоставленной DCU, ядро формирует дерево
устройств — список установленного в системе оборудования, и в соответствии
с этим списком начинает подгружать модули, управляющие устройствами— драйверы.
Подгрузка по-прежнему происходит посредством сервисов вторичного загрузчика
— ведь все драйверы размещены на загрузочном диске и в корневой файловой
системе, в том числе и драйверы самого этого диска и этой файловой системы.

Рис. 3.17. Структура раздела Solaris
Загрузив драйверы всех дисковых устройств и файловых систем (а при загрузке из сети — также сетевых контроллеров и сетевых протоколов), ядро начинает их инициализацию. С этого момента использовать сервисы вторичного загрузчика становится невозможно, но они уже и не нужны. Проинициализировав собственный драйвер загрузочного диска и корневой файловой системы, ядро запускает программу init, которая подключает остальные диски и файловые системы, если они есть, указывает параметры сетевых устройств и инициализирует их, запускает обязательные сервисы, в общем, производит всю остальную стартовую настройку системы.
Существуют ОС, которые не умеют самостоятельно выполнять весь цикл бутстрапа.
Они используют более примитивную операционную систему, которая исполняет
их вторичный (или какой это уже будет по счету) загрузчик, и помогает
этому загрузчику поместить в память ядро ОС. На процессорах х8б в качестве
стартовой системы часто используется MS/DR DOS, а загрузчик новой ОС оформляется
в виде ЕХЕ-файла.
Таким образом устроены системы MS Windows l.x-З.х, Windows 95/98/ME, DesqView
и ряд других "многозадачников" для MS DOS. Таким же образом
загружается сервер Nowell Netware, система Oberon для х86, программы,
написанные для различных расширителей DOS (DOS extenders) и т. д. Многие
Из перечисленных систем, например Windows (версии младше З.11 — в обязательном
порядке, а З.11 и 95/98/МЕ только в определенных конфигурациях) используют
DOS и во время работы в качестве дисковой подсистемы. Тем не менее, эти
программные пакеты умеют самостоятельно загружать Пользовательские программы
и выполнять все перечисленные во введении Функции и должны, в соответствии
с нашим определением, считаться полноценными операционными системами.
