Архитектура и основные компоненты z/VM
Операционная система z/VM построена в соответствии с концепцией интеграции компонентов и включает базовые и опциональные элементы. Базовые элементы служат для поддержки наиболее важных функций и сервисов системы и всегда включаются в установочный пакет z/VM. Опциональные элементы обеспечивают поддержку дополнительных функций операционной системы и могут заказываться по отдельности по желанию пользователя. Полный перечень элементов z/VM представлен в приложении 7. В данной главе будут рассмотрены наиболее важные базовые компоненты z/VM, такие как управляющая программа CP и диалоговый монитор CMS, и показаны основные механизмы ее функционирования.
Архитектура ОС Linux
Linux создавалась как UNIX-подобная операционная система, поэтому принципы ее архитектуры мало чем отличаются от стандартной UNIX. Базовым элементом Linux является ядро (kernel), которое непосредственно взаимодействует с аппаратной частью компьютера, изолируя прикладные программы от особенностей его архитектуры. Ядро обеспечивает выполнение основных функций операционной системы, включая управление процессами и памятью, поддержку файловой системы и управление вводом-выводом. Напомним, что процессами в Linux называют находящиеся в стадии выполнения программы, которые претендуют на получение имеющихся аппаратных ресурсов и данных.
Управление процессами осуществляется планировщиком процессов (scheduler), который создает процессы и управляет распределением ресурсов между ними. В частности, планировщик управляет выделением квантов процессорного времени и осуществляет диспетчеризацию процессов, выбирая для выполнения процесс с наивысшим приоритетом. Для взаимодействия между процессами поддерживается механизм обмена управляющими сигналами, а также обеспечивается возможность обмена данными между различными процессами.
Управление памятью основано на методе страничной организации виртуальной памяти, реализуемом в соответствии с аппаратными особенностями той или иной платформы.
Файловая система Linux обеспечивает унифицированный интерфейс доступа к данным, расположенным на дисковых накопителях и других периферийных устройствах. Файловая система имеет иерархическую организацию, с возможностью объединения файлов в соподчиненные каталоги. Логически данная организация в точности соответствует рассмотренной нами ранее файловой системе HFS UNIX. Файловая система контролирует права доступа к файлу при выполнении различных операций, основываясь на статусе и привилегиях пользователя и запущенных им приложений. Следует отметить, что все периферийные устройства рассматриваются как элементы единой файловой системы Linux.
Управление вводом-выводом заключается в выполнении запросов файловой системы и модуля управления процессами на доступ к различным периферийным устройствам (дискам, принтерам, пользовательским терминалам, сетевым адаптерам и т.п.).
При выполнении операций ввода-вывода организуется разделяемый доступ к устройствам и обеспечивается необходимая буферизация данных. Программную основу ввода-вывода составляют драйверы устройств.
Помимо ядра Linux включает набор утилит и вспомогательных программ, предназначенных для администрирования системы, обслуживания устройств, реализации дополнительных сервисов, разработки приложений и т.д. Особое место здесь занимают средства поддержки пользовательского интерфейса Linux, включающие как традиционные для UNIX-систем версии командного интерпретатора shell, так и графические оболочки (KDE, Gnome). Взаимодействие вспомогательных программ (так же, как и пользовательских приложений) с ядром происходит посредством стандартного интерфейса системных вызовов. Интерфейс системных вызовов (API) представляет собой набор услуг ядра и определяет формат запросов на услуги. Процесс запрашивает услугу посредством системного вызова определенной процедуры ядра, внешне похожего на вызов обычной библиотечной функции.
Сегодня на рынке предлагается несколько различных дистрибутивов Linux от разных поставщиков, предназначенных для установки на различные платформы и в том числе на серверы S/390 и zSeries. IBM рекомендует к использованию три основных дистрибутива [34]:
SuSe Linux Enterprise ServerTurbolinux ServerRed Hat Enterprise Linux
Указанные дистрибутивы используют одно и то же ядро Linux (в настоящее время используется версия 2.6), стандартный набор утилит и компиляторов, общие библиотеки разработки и единый интерфейс системных вызовов (API), а также другие компоненты, характерные для любой версии Linux и независимые от платформы. В частности, дистрибутивы Linux традиционно включают поддержку инфраструктурных сетевых сервисов, таких как DNS, DHCP, NFS, а также установочные пакеты Web-сервера Apache, proxy-сервера Squid, почтового сервера SMTP и др.
В то же время версии, ориентированные на серверы S/390 и zSeries, включают ряд специфических аппаратно-зависимых компонентов и функций.Помимо базовых средств Linux каждый разработчик обычно включает в дистрибутив несколько эксклюзивных "фирменных" компонентов, предназначенных для поддержки дополнительных сервисов и средств администрирования. В приложении 8 представлены основные функциональные компоненты дистрибутива SuSe Linux Enterprise Server. Как было отмечено выше, IBM предлагает практически все свои основные программные продукты промежуточного слоя (middleware) для использования в Linux. Перечень этих продуктов представлен в приложении 9.
Диалоговый монитор z/VM
Диалоговый монитор CMS (Conversational Monitor System) является базовым компонентом z/VM и представляет собой высокопроизводительную операционную среду, ориентированную на поддержку интерактивных пользователей при решении следующих задач [32]:
создание, отладка и тестирование прикладных программ для использования в CMS или гостевых ОС;выполнение приложений, разработанных для CMS или гостевых ОС;создание и редактирование файлов данных;манипулирование файлами данных;выполнение заданий в пакетном режиме;разделение данных между CMS и гостевыми ОС;организация взаимодействия между пользователями CMS и гостевых ОС.
Диалоговый монитор запускается на отдельной виртуальной машине либо по команде пользователя (IPL CMS), либо автоматически при запуске виртуальной машины, если есть соответствующее указание в справочнике пользователей CP. Фактически CMS выполняет две главные функции: обеспечивает поддержку интерфейса для конечного пользователя z/VM и предоставляет интерфейс прикладного программирования (API) для пользовательских приложений.
В среде CMS пользователь сохраняет возможность использования команд управляющей программы CP, а также располагает набором собственных команд CMS, предназначенных для создания и выполнения приложений, управления данными, в том числе с использованием полноэкранных диалоговых средств.
Диалоговый монитор содержит необходимые средства для организации хранения и доступа к данным во внешней памяти. Для дисковых устройств (DASD) поддерживается три основных типа файловых систем:
базовая файловая система CMS на мини-дисках;разделяемая файловая система SFS;байтовая файловая система BFS.
Основной единицей хранения данных в CMS являются файлы. Имя файла состоит из собственно имени и типа файла, разделенных точкой. Имя и тип могут содержать до восьми алфавитно-цифровых и некоторых специальных символов, например: PRG#1.ASSEMBLE, BATCH:X.SOURCE, CHANGE.EXEC, MY_DOC.TEXT и т.п. Некоторые значения типов файлов являются стандартными и формируются системой автоматически.
Помимо имени файл характеризуется двумя атрибутами: буквенным (file mode letter) и числовым (file mode number). Буквенный атрибут (A-Z) указывает на место размещения файла (мини-диск или директория SFS), а числовой (0-6) - на режим использования и обслуживания файла. Например, числовой атрибут 1 означает возможность использования файла для чтения и записи, числовой атрибут 3 предписывает уничтожить файл после чтения и т.п. Файлы CMS различаются по формату логических записей (постоянной или переменной длины), однако в большинстве случаев система определяет необходимые характеристики записей автоматически. CMS поддерживает необходимый набор команд для обслуживания файлов (создание, редактирование, копирование, удаление и др.).
Файлы z/VM могут размещаться либо на так называемых мини-дисках, либо в файловом пространстве разделяемой файловой системы SFS (Shared File System).
Мини-диск представляет собой непрерывный участок реального дискового накопителя, состоящий из смежных цилиндров (вплоть до целого диска). С точки зрения пользователя мини-диски являются аналогом независимого дискового тома. Каждый мини-диск характеризуется логическим номером, именем (меткой), объемом выделенного пространства (в цилиндрах), режимом разрешенного доступа. В z/VM могут использоваться три типа мини-дисков:
постоянные - определяются в справочнике пользователя виртуальной машины и доступны в рамках каждого пользовательского сеанса;временные - создаются в ходе пользовательского сеанса и автоматически уничтожаются при его завершении;виртуальные - эмулируются по запросу пользователя в виртуальной памяти (не используют реальный диск).
Мини-диски могут быть доступны только одной виртуальной машине, но могут при соответствующей авторизации использоваться несколькими виртуальными машинами совместно.
Каждый мини-диск располагает главным каталогом (master file directory), в котором описаны атрибуты размещения всех хранящихся на мини-диске файлов, используемые для доступа.
Разделяемая файловая система SFS (Shared File System) является расширением базовой файловой системы CMS и обеспечивает более эффективное использование дискового пространства, а также возможность совместного доступа к файлам других виртуальных машин при наличии соответствующей авторизации.
Для размещения файлов в SFS для всех виртуальных машин (пользователей) предоставляется место в специальным образом сконфигурированной области жесткого диска, называемой файловый пул (file pool). Файлы могут объединяться в соподчиненные каталоги (directory), как это происходит в иерархических файловых системах, правда количество уровней подчиненности ограничено восемью. Каталогам присваиваются имена (dirname), состоящие не более чем из 16 алфавитно-цифровых символов. Старший в иерархии каталог (top directory) создается автоматически при выделении пользователю места в файловом пуле и его имя совпадает с именем пользователя.
Пользователь имеет неограниченный доступ к собственным файлам и каталогам, в то время как хранящиеся в том же пуле файлы других пользователей обычно недоступны. В SFS существует возможность организации совместного (разделяемого) доступа к файлам путем передачи полномочий другим пользователям от пользователя-владельца. При этом управление доступом может производиться на уровне как отдельных файлов, так и целых каталогов.
z/VM предоставляет возможность реализации эффективных средств администрирования и управления файлами и каталогами SFS с помощью компонента DFSMS/VM. Данный компонент может автоматически производить, например, удаление файлов с истекшим сроком хранения, архивирование, резервное копирование и восстановление файлов, если для файла установлено соответствующее значение атрибута "класс управления" (management class).
Компонент z/VM OpenExtensions обеспечивает поддержку еще одного типа файловой системы, получившей название байтовая файловая система BFS (Byte File System), использующая иерархическую организацию хранения файлов, характерную для операционной системы UNIX. Аналогичную структуру имеет файловая система HFS операционной системы z/OS, рассмотренная в п. 5.1.6. Название BFS подчеркивает особенность внутренней организации файлов UNIX как байт-ориентированных, т.е. не разделяемых на уровне ОС на логические записи. В z/VM поддерживаются средства копирования и перемещения файлов между BFS и базовой файловой системой CMS.
Назначение и возможности z/VM
Операционная система z/VM представляет второе направление операционных систем IBM, ориентированных на платформу zSeries. z/VM построена на основе концепции "виртуальных машин" (Virtual Machine), которая означает, что в рамках одной системы может одновременно функционировать множество виртуальных машин, каждая из которых функционально эквивалентна реальной ЭВМ. Каждая виртуальная машина использует свою часть ресурсов системы (процессорное время, оперативную память, периферийные устройства).
Таким образом, z/VM, разделяя ресурсы ЭВМ между множеством виртуальных машин, предоставляет возможность параллельной работы на одном сервере как отдельных пользователей и системно-независимых приложений, так и различных операционных систем, включая диалоговый монитор z/VM, а также OS/390, z/OS, Linux и др. Операционные системы, запускаемые в рамках виртуальной машины z/VM, называют гостевыми. Гостевые операционные системы конфигурируются как независимые системы для поддержки своего круга пользователей и решения определенного набора задач. z/VM поддерживает в качестве гостевых операционные системы, предназначенные для z/Architecture и архитектуры ESA/390.
Возможности виртуальных машин z/VM позволяют использовать их для решения широкого круга практических задач, среди которых необходимо выделить следующие:
тестирование новых системных, телекоммуникационных и других приложений, которое нецелесообразно проводить в рабочем режиме из-за возможности сбоев или краха операционной системы;тестирование и настройка новых версий операционных систем параллельно с функционированием старых версий в рабочем режиме;проведение обучения и тренинга персонала.
z/VM может служить основой для создания и развертывания гетерогенных корпоративных систем масштаба предприятия благодаря поддержке целого ряда промышленных стандартов, протоколов и интерфейсов. В частности, z/VM располагает современными средствами поддержки сетевых вычислений (Internet/intranet) на основе TCP/IP, SNA, Java и многочисленных сетевых протоколов, таких как Ethernet, FDDI, FTP, VLAN, NFS, SMTP, Token Ring, UDP, X.25, X-Windows, SNMP, NetView.
z/ VM поддерживает стандарты открытых систем POSIX и XPG, предоставляя интерфейс системных вызовов для UNIX-приложений и пользовательскую среду shell в рамках сервиса разработки приложений OpenExtensions. Это позволяет как выполнять готовые POSIX-совместимые приложения, так и разрабатывать новые.
Одна из важных областей применения z/VM - использование в качестве серверной платформы для поддержки клиентов локальных вычислительных сетей. Данное решение предоставляет огромному числу пользователей все преимущества мэйнфрейма, включая высокую надежность и производительность, большие объемы внешней памяти, быстрые коммуникации. В частности, поддерживаемый z/VM клиент-серверный продукт Tivoli Storage Manager for VM обеспечивает резервное копирование, архивирование и восстановление файлов рабочих станций, работающих под управлением MS Windows, Linux, Apple Macintosh и OS/2. Значительное внимание IBM уделяет архитектурным решениям, основанным на консолидации Linux-серверов под управлением z/VM.
Предшественницей z/VM была операционная система VM/ESA, ориентированная на 32-разрядную платформу S/390. В VM/ESA были реализованы основные технологические принципы и решения, положенные в основу z/VM. Первая версия z/VM V3R1, представленная в 2000 году, как и последующие выпуски, обеспечивают полную поддержку как существующих серверов zSeries, так и серверов S/390 (Parallel Enterprise Server G5/G6, Multiprise 3000). При установке z/VM на серверы zSeries появляется возможность в качестве гостевых систем использовать 64-разрядные OS/390 V2R10, z/OS и Linux для zSeries, а также операционные системы ESA/390, в том числе OS/390, VSE/ESA, TPF и Linux для S/390. z/VM снимает ограничение на объем основной памяти 2 GB, что открывает новые возможности в отношении увеличения производительности при обслуживании большего числа пользователей и гостевых систем. На данный момент выпущена четвертая версия z/VM V4R4 [30].
Общая характеристика ОС Linux
Операционная система Linux, разработанная в начале 90-х годов по инициативе энтузиаста-одиночки, в настоящее время превратилась в полноценную, высокоэффективную и надежную серверную ОС, получившую признание и широкое распространение во всем мире. Одной из важнейших отличительных особенностей Linux является открытость исходного кода, что дает возможность контролировать ее использование и при необходимости вносить изменения. Операционная система Linux (любые дистрибутивы и версии) распространяется на основе генеральной общественной лицензии GPL (General Public License), позволяющей свободно использовать, модифицировать и распространять программные продукты в первоначальном или измененном виде, как на коммерческой, так и на некоммерческой основе. Благодаря участию в разработке и тестировании ОС Linux сотен тысяч программистов во всем мире, программный код системы быстро развивается и совершенствуется. Это создало предпосылки для признания Linux в качестве системы с высокой степенью надежности и безопасности, подтвержденной международным сертификатом Common Criteria (ISO/IEC 15408). Данный сертификат свидетельствует о возможности использования Linux при решении критически важных задач, например, в банковских и военных системах.
В 1999 году IBM завершила работу по переносу и адаптации операционной системы Linux для платформы S/390. Этот неожиданный для многих специалистов "ход" позволил объединить два принципиально различных направления в использовании средств вычислительной техники: системы обработки данных на базе мэйнфреймов с акцентом на высокую производительность и безопасность и независимую от аппаратной платформы операционную систему с открытым исходным кодом. Данное решение оказалось чрезвычайно привлекательным и продуктивным для многих пользователей в силу следующих причин:
большое количество существующих и высокий темп появления новых приложений для Linux, причем большая часть из них распространяется бесплатно;возможность переноса UNIX-приложений в Linux;обеспечение высокой степени переносимости приложений между всеми платформами, поставляемыми IBM;поддержка программного обеспечения промежуточного слоя, выпускаемого компанией IBM: DB2 UDB, MQSeries, Websphere Application Server, продукты семейства Tivoli, IBM Java Virtual Machine;гибкость, открытость, надежность и безопасность Linux в сочетании с классическими преимуществами мэйнфреймов;высокая степень масштабируемости за счет возможности объединения большого числа Linux-серверов на одной машине;снижение расходов на эксплуатацию и развитие системы.
Linux для zSeries поддерживает все стандарты и интерфейсы, принятые в других версиях Linux. В частности, используется стандарт кодирования символов ASCII, применяются традиционные пользовательские интерфейсы (shell и XWindow), поддерживаются стандарты POSIX и XPG, обеспечивающие переносимость приложений на уровне исходного кода между различными платформами, используются общие средства разработки, реализуются многочисленные сетевые сервисы на базе протокола TCP/IP.
Особенности реализации ОС Linux на платформе zSeries
Первая версия Linux для мэйнфреймов (Linux for S/390) может устанавливаться на серверы S/390 и z900 и поддерживает только 31-разрядный режим работы. Выпущенная в 2001 году версия Linux for zSeries поддерживает 64-разрядную архитектуру zSeries как в реальном, так и в виртуальном режиме, и может устанавливаться на все серверы классов z800 и z900.
Важной особенностью применения операционной системы Linux для zSeries является использование во всех моделях серверов специализированных процессорных устройств IFL (Integrated Facility for Linux). Эти устройства ориентированы исключительно на поддержку рабочих нагрузок ОС Linux, запускаемой в режиме LPAR, в том числе и под управлением z/VM. Процессоры IFL не приводят к увеличению платы за программное обеспечение zSeries, выполняемое на других процессорах.
Существует три основных варианта установки и использования образов операционной системы Linux на платформе zSeries (рис. 5.68) [35]:
Базовый (native).В логические разделы (LPAR).В качестве гостевой системы z/VM.

Рис. 5.68. Варианты установки Linux: базовый (a), в логические разделы LPAR (b), в качестве гостевой ОС в z/VM (с)
В базовом варианте Linux является единственной операционной системой, устанавливаемой на сервер, и полностью использует все имеющиеся ресурсы, включая процессоры, физическую память и устройства ввода-вывода. Недостатком такого способа является необходимость использования аппаратной консоли для перезагрузки системы. На платформах z/990 и z/890 данный вариант не поддерживается.
Во втором варианте установка Linux производится в логические разделы LPAR с возможностью использования выделенной части физической памяти и некоторого числа процессоров. В этом варианте может быть запущено несколько независимых образов Linux или других операционных систем, каждая в своем логическом разделе (всего до 30 LPAR). Однако при загрузке и перезагрузке раздела Linux, а также для переопределения параметров раздела требуется доступ к аппаратной консоли.
В третьем варианте Linux запускается в качестве гостевой операционной системы под управлением z/VM на одной или нескольких виртуальных машинах. При этом может быть запущено несколько сотен образов Linux вместе с образами других операционных систем и диалоговыми мониторами CMS. Количество используемых виртуальных машин ограничивается имеющимися ресурсами системы. Разделяемый доступ к устройствам, а также высокоскоростное взаимодействие между гостевыми системами в этом случае поддерживаются на уровне z/VM. Важным преимуществом данного варианта является использование каждой виртуальной машиной собственной защищенной виртуальной системной консоли, доступ к которой может быть организован с помощью стандартных сетевых средств (telnet, rlogin, TN3270 и т.п.). Это позволяет осуществлять удаленное администрирование образов Linux, включая загрузку и перезагрузку системы. Конечно, использование данного варианта установки Linux потребует знаний и навыков работы в операционной системе z/VM.
В любом варианте установки начальная загрузка Linux производится по локальной сети с предварительным размещением установочных файлов (пакетов) на FTP- или NFS-сервере.
Основные коммуникационные возможности Linux для zSeries реализуются на основе протокола TCP/IP с помощью сетевого адаптера OSA, который поддерживает стандарты Token-Ring, Ethernet, Fast Ethernet, FDDI и ATM. Кроме того, реализована поддержка адаптера "канал-канал" (CTCA), а также возможность прямого взаимодействия с другими системами и устройствами, используемыми на платформе zSeries. В качестве гостевой системы z/VM Linux поддерживает все средства виртуализации сетевого взаимодействия, включая vCTC, IUCV, а также VM Guest LAN.
Системные решения на основе z/VM и Linux
Как уже отмечалось, одним из вариантов применения Linux на платформе zSeries является использование инсталляции Linux в качестве гостевой операционной системы в составе z/VM. Этот вариант представляется наиболее гибким с точки зрения использования возможностей платформы zSeries и рекомендуется IBM как самый экономичный и эффективный для большого числа систем электронного бизнеса [36].
z/VM позволяет устанавливать сотни образов Linux на один сервер, обеспечивая все необходимые средства для поддержки требуемой функциональности и организации эффективного взаимодействия между ними. Такая возможность, получившая название консолидация серверов (рис. 5.69), является хорошей альтернативой для построения распределенных корпоративных информационных систем, использующих большое число функциональных серверов на различных платформах (Intel, HP, Sun и др.). Решение, основанное на использовании консолидированных серверов Linux на платформе zSeries, наряду с ее общими достоинствами дает следующие неоспоримые преимущества:
уменьшение штата администраторов и расходов на администрирование и техническое обслуживание;снижение времени и расходов на установку (образ Linux может быть инсталлирован за несколько минут);использование технологии виртуальных сетей для организации взаимодействия серверов Linux (повышает быстродействие, избавляет от необходимости приобретать сетевое оборудование и строить кабельную систему);использование общего дискового пространства (приводит к устранению дублирования данных);более эффективное использование процессорного времени и других ресурсов (сокращение времени простоев, увеличение загрузки).

Рис. 5.69. Консолидация серверов Linux на базе z/VM
При возрастании нагрузки консолидированная система легко масштабируется, как вертикально, так и горизонтально. Вертикальное масштабирование означает увеличение количества системных ресурсов, предоставляемых виртуальной машине. Горизонтальное масштабирование
реализуется путем добавления необходимого числа виртуальных машин с образами Linux.
Новый виртуальный сервер Linux конфигурируется в течение нескольких минут, при этом затраты несопоставимы с установкой дополнительного реального сервера. Эффект от масштабирования возрастает при использовании виртуальных дисков, так как при этом данные размещаются в основной памяти. Важным достоинством консолидированного решения является возможность динамического (on line) перераспределения ресурсов между серверами Linux при изменении рабочей нагрузки.
Использование Linux под управлением z/VM создает удобные возможности для разработки, отладки и тестирования информационных систем, использующих zSeries, поскольку среда z/VM является более гибкой и простой в обслуживании, нежели логические разделы LPAR. z/VM включает встроенные средства отладки, позволяющие запускать виртуальные машины в пошаговом режиме, устанавливать контрольные точки, проверять содержимое памяти и регистров. Возможности тестирования расширяются за счет эмуляции устройств, которые могут физически отсутствовать в данной конфигурации.
Рассмотрим еще один пример, иллюстрирующий способ повышения эффективности функционирования информационной системы и сокращения эксплуатационных затрат за счет перехода с трехуровневой на двухуровневую архитектуру, построенную на основе технологий, доступных на платформе zSeries. На рис. 5.70 показано, каким образом можно осуществить такой переход. В трехуровневой системе (a) роль сервера данных традиционно отводится мэйнфрейму, работающему под управлением OS/390 или z/OS на платформе S/390 (z900). В то же время бизнес-логика размещается на множестве распределенных серверов приложений, использующих менее мощные серверные компьютеры.
Перенос серверов приложений в среду виртуальных машин Linux, работающих под управлением z/VM на платформе z900 (z990), позволяет получить двухуровневую аппаратную конфигурацию (b). Образы операционных систем z/OS и z/VM выполняются в отдельных логических разделах LPAR. При этом реальная вычислительная сеть, связывающая серверы данных с серверами приложений, заменяется средствами, реализуемыми технологией HiperSockets, которая обеспечивает эмуляцию сетевого соединения между LPAR-системами на основе прямого высокоскоростного взаимодействия по принципу "память-память".Взаимодействие между серверами приложений Linux может быть построено на основе виртуальной гостевой сети VM Guest LAN.
Следует обратить внимание, что такая реконфигурация, получившая название "интеграция приложений", не потребует перепроектирования программного обеспечения информационной системы, сохраняя на программном и логическом уровнях по-прежнему трехуровневое взаимодействие.

Рис. 5.70. Переход с трехуровневой (a) на двухуровневую (b) архитектуру информационной системы
Управляющая программа z/VM
Управляющая программа CP (Control Program) z/VM выполняет функции менеджера виртуальных машин, включая создание программных образов виртуальных машин для каждого пользователя, распределение ресурсов физической ЭВМ между виртуальными машинами, а также организацию взаимодействия между приложениями, выполняющимися на разных виртуальных машинах. По этой причине управляющую программу CP иногда называют гипервизором (hypervisor).
Виртуальные машины, создаваемые управляющей программой CP, различаются по режиму работы [33]. Для работы на серверах zSeries обычно выбирают режим ESA (или эквивалентный XA). В этом случае, если управляющая программа сконфигурирована для работы в 32-разрядном режиме, виртуальная машина будет соответствовать архитектуре ESA/390. Для 64-разрядной инсталляции CP данный режим позволяет выполнять как 32-разрядные, так и 64-разрядные приложения, используя все возможности z/Architecture. Режим XC основан на так называемой ESA/XC архитектуре, обеспечивающей разделяемый доступ виртуальных машин к пространствам данных z/VM.
Виртуальная машина может получить в свое распоряжение до 64 виртуальных процессоров, которые будут предоставляться гостевой ОС для диспетчеризации выполняемых ею работ. При этом будет использоваться лишь некоторое число реальных процессоров, среди которых могут быть процессоры, закрепленные за данной виртуальной машиной, или же разделяемые с другими.
Управление памятью в z/VM основано на концепции множественных виртуальных адресных пространств размером 2 GB для 32-разрядного режима и 16 ЕB для 64-разрядного. Управляющая программа CP всегда размещается в первой секции любого адресного пространства (рис. 5.66). По запросу пользователя CP создает виртуальную машину, выделяя ей новое адресное пространство, и загружает туда диалоговый монитор CMS или гостевую операционную систему. Диалоговый монитор является "штатной" операционной системой в составе z/VM, ориентированной на поддержку пользователя. После этого средствами CMS или операционных систем в адресные пространства может производиться загрузка собственных приложений.

Рис. 5.66. Виртуальные адресные пространства z/VM
С точки зрения используемой конфигурации памяти различают три типа виртуальных машин:
V=R (Virtual=Real) машина получает в свое распоряжение фиксированный непрерывный участок основной памяти, начинающийся с нулевого адреса.V=F (Virtual=Fixed) машина получает в свое распоряжение фиксированный непрерывный участок основной памяти, начинающийся с адреса, отличного от нулевого.V=V (Virtual=Virtual) машина не может непосредственно использовать основную память.
Первые два типа относят к привилегированным типам виртуальных машин. На таких машинах управление выделенной основной памятью берет на себя гостевая ОС в соответствии с ее внутренними механизмами. В третьем случае виртуальной машине выделяется виртуальная память, управляемая CP. Она имеет страничную организацию и поддерживает стандартный механизм динамического преобразования адресов с возможностью межпространственной связи на основе регистров доступа.
Использование периферийных устройств виртуальной машиной производится одним из четырех способов. Способ закрепления (exclusive) означает выделение реального устройства в полное распоряжение виртуальной машины. Способ разделения (shared) допускает одновременное использование реального устройства несколькими виртуальными машинами. Способ накопления (spooled) основан на выделении реальному устройству области жесткого диска (спула), которая используется для накопления вводимой и выводимой информации. Обмен данными между спулом и реальным устройством контролируется управляющей программой. Способ симуляции
(simulated) означает программное моделирование работы некоторых устройств, которые физически не используются в системе (например, сетевые устройства связи для взаимодействия виртуальных машин).
Для работы с управляющей программой CP пользователю предоставляется набор команд, с помощью которых производится создание и конфигурирование виртуальных машин, администрирование пользователей, управление устройствами, информирование о работе системы и т.д.
Доступ к z/ VM осуществляется через консоль, назначаемую терминальному устройству или эмулируемую на рабочей станции. Множество команд, доступных пользователю, и, следовательно, возможности управления зависят от установленного для данного пользователя класса (классов) привилегий. В z/VM установлено семь основных стандартных классов привилегий, обозначаемых латинскими буквами A-G, в соответствии с ролью пользователя в системе [31]:
A (системный оператор) - управление системой виртуальных машин и доступом пользователей к системе, настройка параметров производительности и сбор информации о системе;B (системный оператор ресурсов) - управление всеми реальными устройствами z/VM;C (системный программист) - настройка системных конфигурационных параметров;D (оператор спула) - управление устройствами, использующими метод накопления, и настройка спула;E (системный аналитик) - контроль и управление хранением системных данных;F (инженер по сервисному обслуживанию) - получение и анализ данных о работе оборудования;G (обычный пользователь) - управление работой отдельной виртуальной машины;
Кроме перечисленных, поддерживается класс команд Any, доступных любому пользователю, независимо от привилегий, а также существует возможность создавать пользовательские классы для собственных нужд.
Важнейшим элементом управляющей программы CP является создаваемый системным оператором справочник пользователей (user directory), содержащий описание всех виртуальных машин, которые могут быть запущены в системе. Каждый элемент справочника содержит перечень основных параметров виртуальной машины, включающий: идентификатор пользователя (logon ID) и пароль, класс привилегий, начальную конфигурацию используемых устройств, объем памяти, режим работы, параметры использования процессорного времени и некоторые другие. Обычно справочник пользователей создается на этапе инсталляции системы, но может быть изменен в процессе работы.
Запуск зарегистрированной в справочнике виртуальной машины производится по инициативе пользователя, когда он вводит команду LOGON.После завершения инициализации на основе указанных параметров пользователь получает возможность выполнять различные команды в соответствии с назначенным классом привилегий, в том числе запустить диалоговый монитор CMS или гостевую операционную систему.
Виртуализация сетевого взаимодействия в z/VM
Обмен данными между гостевыми операционными системами в z/VM основан на организации виртуальных сетей, которые обеспечивают взаимодействие без использования реальных сетевых устройств. Очевидно, что такое решение существенно увеличивает скорость обмена без каких-либо дополнительных расходов.
В z/VM поддерживается три типа виртуальных сетей.
Виртуальный канал vCTC (Virtual Channel-to-Channel) - обеспечивает прямое соединение ("точка-точка") между гостевыми системами в соответствии с канальным протоколом, реализуемым в реальном устройстве CTC.Межпользовательский коммуникационный передатчик IUCV (Inter-user communication vehicle) - используется для прямого взаимодействия ("точка-точка") между виртуальными машинами на основе TCP/IP-протокола.Гостевая локальная вычислительная сеть (VM Guest LAN) - базируется на эмуляции локальной вычислительной сети для множества гостевых систем. Два варианта реализации: первый основан на применении технологии HiperSockets, а второй использует эмуляцию реальной сети на базе адаптеров OSA.
На рис. 5.67 представлен пример виртуальной сети z/VM, которая может быть построена c использованием указанных выше возможностей. Две группы гостевые операционных систем (G11-G1N и G21-G2N) образуют две виртуальных подсети типа VM Guest LAN, каждая из которых взаимодействует со "своим" виртуальным маршрутизатором. Виртуальный маршрутизатор представляет собой отдельную виртуальную машину, связанную через реальный сетевой интерфейс (здесь использован адаптер OSA) с внешней вычислительной сетью. Взаимодействие маршрутизатора с гостевыми ОС может быть организовано любым способом, включая vCTC, IUCV или виртуальный HiperSockets.

Рис. 5.67. Виртуальная сеть z/VM
Отметим, что область действия виртуальной сети ограничена рамками одного образа z/VM, то есть не может быть использована для взаимодействия между системами, работающими в различных логических разделах LPAR.
IBM WebSphere Edge Server for Multiplatform
Edge Server распределяет обработку приложений по сети, передавая Web-данные на вторичные серверы и серверы кэширования. Это приводит к разгрузке серверов приложений и каналов передачи данных, сокращению времени реакции системы (в частности, благодаря кэшированию). На рис. 6.7 показана архитектура информационной системы с Edge Server. Edge Server перехватывает запрос к серверу приложений и генерирует запрос со своим адресом, как адрес источника. Сервер приложений обрабатывает запрос и формирует ответ, который Edge Server кэширует и переправляет клиенту. В случае повторения запроса ответ может извлекаться из кэша, разгружая сервер приложений.
IBM WebSphere Personalization for Multiplatform
IBM WebSphere Personalization упрощает задачу разработки настраиваемых сайтов благодаря включению в WebSphere Application Server следующих механизмов:
Механизм применения правил - применяет бизнес-правила, которые определяют содержимое, отображаемое для каждого посетителя сайта.Механизм распределения ресурсов - позволяет системе персонализации во время выполнения опрашивать базы данных, в которых хранятся профили клиентов, чтобы на этой основе формировать персонализированные страницы.Механизм выработки рекомендаций - использует общие возможности фильтрации, чтобы предлагать посетителям сайта информацию и рекомендации по продуктам, что позволяет организовать встречные продажи и распродажи.
IBM WebSphere: программные продукты группы Foundation & Tools
Состав программных продуктов, относящихся к Foundation & Tools, показан на рис. 6.4. В него входят средства Foundation (Ядро системы) и инструментальные средства разработки Web-приложений (Tools).

Рис. 6.4. IBM WebSphere: программные продукты группы Foundation & Tools
Ядром системы является семейство серверов приложений IBM WebSphere Applications Servers, а также <диспетчер запросов> IBM WebSphere Edge Server for Multiplatforms и IBM Web Sphere Personalization for Multiplatforms.
К средствам разработки (Tools) относятся два семейства программных продуктов: IBM Visual Age и IBM WebSphere Studio.
IBM WebSphere: программные продукты группы Business Portals
В эту группу обычно включают два семейства программных продуктов: семейство IBM WebSphere Portal и семейство IBM WebSphere Commerce (см. рис. 6.8).
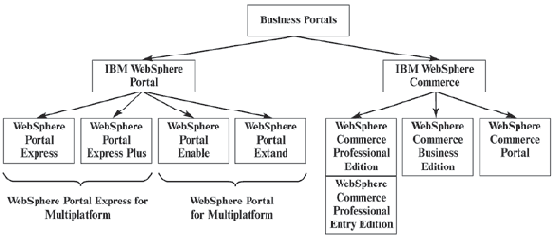
Рис. 6.8. IBM WebSphere: Программные продукты группы Business Portals
В эту группу обычно включают два семейства программных продуктов: семейство IBM WebSphere Portal и семейство IBM WebSphere Commerce (см. рис. 6.8).
Рис. 6.8. IBM WebSphere: Программные продукты группы Business Portals
WebSphere Business Integration Modeler состоит из следующих компонентов:
WebSphere Business Integration Workbench;WebSphere Business Integration Workbench Server.
WebSphere Business Integration Workbench - приложение, работающее совместно с WebSphere Business Integration Workbench Server и предназначенное для тестирования, анализа, имитации и проверки моделей бизнес-процессов и программных средств.
WebSphere Business Integration Workbench включает следующие компоненты: Business Modeler, UML Modeler и XForm Designer.
Business Modeler предоставляет следующие возможности:
моделирование процессов: использует интуитивно понятные средства для преобразования сложных бизнес-процессов в простые для восприятия;позволяет просматривать бизнес-процессы в детализированном виде;бизнес- анализ: использует мощные аналитические средства для выбора оптимальных бизнес-процессов;имитация функционирования: имитирует выполнение процессов в различных условиях; интеграция рабочих потоков: преобразование моделей процессов с помощью языка Flow Definition Language (FDL) и экспорт их в WebSphere MQ Workflow для реализации.
UML (Unified Modeling Language - унифицированный язык моделирования) Modeler позволяет представлять данные и модели в формате объектного языка UML. Это дает возможность экспорта данных в инструментальные среды быстрой разработки приложений (такие, как Rational Rose), а также импорта в систему объектных моделей, представленных средствами UML.
XForm Designer предоставляет возможность быстро создавать GUI интерфейсы пользователей, использовать макеты интерфейсов, конвертировать макеты интерфейсов в XML-формат для применения их в других средствах разработки.
WebSphere Business Integration Workbench Server - это приложение J2EE, которое может быть размещено на WebSphere Application Server или на других аналогичных платформах. Продукт предоставляет средства управления репозиторием и Web-публикациями.
WebSphere Business Integration Workbench Server состоит из двух основных компонентов: Repository (репозиторий) и Web Publisher.
ПО WebSphere Business Integration Server предназначено для следующих целей:
поддержка звездообразных топологий;использование концепции общих бизнес-объектов в промежуточном ПО для интеграции;использование технологии XML, позволяющей в рабочем цикле совместно использовать артефакты и общие бизнес-объекты.
С помощью WebSphere Business Integration Server можно быстро интегрировать новые или существующие приложения на различных платформах или быстро создавать и разворачивать новые бизнес-процессы.
Основные компоненты IBM WebSphere Business Integration Server показаны на рис. 6.10.
WebSphere Interchange Server - координирует деятельность бизнес-процессов, распространяющуюся на несколько приложений, которые могут быть географически локальными или удаленными, внутренними или внешними для организации.
WebSphere MQ Workflow - координирует долговременную деятельность, которая распространяется на различные системы и группы сотрудников. Это ПО позволяет строить модели бизнес-процессов и управлять их выполнением (см. также раздел 6.4).
WebSphere MQ Integrator Broker - координирует информационные потоки путем преобразования, интеллектуальной маршрутизации и дополнения текущих сообщений в различных разрозненных бизнес-системах.

|
| © 2003-2007 INTUIT.ru. Все права защищены. |
Электронный бизнес и требования к IT-инфраструктуре
С середины 90-х годов руководители многих компаний во всем мире начали осознавать, что истинное значение Internet заключается не в просмотре Web-страниц и пользовании электронной почтой, а в тех новых возможностях, которые он открывает для совершенствования деловых процессов, сокращения затрат и увеличения прибыли предприятий. Электронный бизнес - это не просто электронный вариант торговых сделок, его задача - использовать современные технологии для реорганизации бизнес-процессов с целью улучшения обслуживания клиентов.
Предприятия должны уметь быстро реагировать на запросы, постоянно модернизировать свои бизнес-процессы, идти в ногу с современными технологиями. Реализовать это можно, лишь сформировав достаточно гибкую IT-инфраструктуру, способную быстро внедрять новые технологии и своевременно изменять направленность и функциональные возможности приложений.
Выделяют четыре основные фазы перехода предприятий к модели электронного бизнеса.
Чаще всего предприятия начинают с размещения в Web сведений рекламно-ознакомительного характера о себе, используя Internet как способ информирования клиентов о своей деятельности. Такое применение Internet не может заметно увеличить прибыльность компании. Более существенных результатов можно достичь, перейдя в следующую фазу электронного бизнеса, когда заказчикам предоставляется доступ к основным информационным ресурсам компании с тем, чтобы они могли запрашивать нужную им информацию, например, выяснять состояние банковского счета или совершать реальные онлайновые сделки. Поскольку в этих сделках задействованы конфиденциальные данные, такие, как номера банковских счетов или кредитных карточек, предприятия вынуждены формировать безопасную среду для работы своих приложений.
Следующая фаза - предприятия адаптируют свои бизнес-процессы к новым технологиям, реорганизуя при необходимости всю деятельность компании, переориентируя ее на удовлетворение потребностей заказчиков и предоставление им новых услуг. К новым услугам можно отнести, например, возможности интерактивно заказывать товары и услуги, проверять наличие товара на складе и быть в курсе состояния своих заказов в течение всего процесса их выполнения.
Для таких типов приложений электронного бизнеса требуется сквозная интеграция и полная прозрачность всех процессов в рамках организации.
Наконец, четвертая фаза - это объединение бизнес-процессов компании с бизнес-процессами партнеров и клиентов.
Компания IBM в 2002 году анонсировала свое видение современной фазы развития электронного бизнеса, назвав ее <электронный бизнес по требованию> (business on demand).
<Бизнес по требованию - это способ организации деятельности предприятия, при котором его бизнес-процессы интегрированы с бизнес-процессами ключевых бизнес-партнеров, поставщиков и клиентов и способны быстро реагировать на любые потребности заказчиков, перспективные рыночные возможности и внешние угрозы> [6.2].
Для поддержки <электронного бизнеса по требованию> информационная инфраструктура (IT-инфраструктура) должна быть гибкой, масштабируемой, надежной, самоуправляемой, экономной. Она должна обеспечить возможности [6.1]:
быстрого создания и развертывания приложений, разработки приложений на основе открытых стандартов;работы в гетерогенной среде;включения в орбиту электронного бизнеса любых устройств, новых партнеров, поддержки новых языков и национальных стандартов при минимизации объема работ по изменению кодов и повторному развертыванию приложений.
Построение такой IT-инфраструктуры связано с деятельностью в трех направлениях:
интеграция (Integration): создание средств для взаимодействия и совместной работы персонала, унифицированного представления и взаимодействия рабочих процессов, доступа в реальном времени к распределенной и разнотипной информации;автоматизация (Automation): внедрение средств автоматизированного управления информационной инфраструктурой;виртуализация (Virtualization): применение эффективных современных методов размещения и использования информационных, вычислительных и других видов ресурсов информационных систем.
Интеграция должна обеспечить следующие возможности:
оперативного взаимодействия и совместного доступа к данным сотрудникам предприятия, поставщикам и клиентам;доступа к данным в любое время и с помощью любых средств (телефон, карманный компьютер и пр.);быстрой адаптации пользователей к изменениям в информационной системе (путем использования стандартных интерфейсов, порталов для доступа к приложениям и т.д.);взаимодействия приложений на основе использования общепринятых стандартов и открытых технологий;оперативной модернизации старых приложений и перестройки бизнес-процессов при изменениях в бизнесе;доступа к данным независимо от их источника, местоположения и платформы;консолидации данных.
Для таких типов приложений электронного бизнеса требуется сквозная интеграция и полная прозрачность всех процессов в рамках организации.
Наконец, четвертая фаза - это объединение бизнес-процессов компании с бизнес-процессами партнеров и клиентов.
Компания IBM в 2002 году анонсировала свое видение современной фазы развития электронного бизнеса, назвав ее <электронный бизнес по требованию> (business on demand).
<Бизнес по требованию - это способ организации деятельности предприятия, при котором его бизнес-процессы интегрированы с бизнес-процессами ключевых бизнес-партнеров, поставщиков и клиентов и способны быстро реагировать на любые потребности заказчиков, перспективные рыночные возможности и внешние угрозы> [6.2].
Для поддержки <электронного бизнеса по требованию> информационная инфраструктура (IT-инфраструктура) должна быть гибкой, масштабируемой, надежной, самоуправляемой, экономной. Она должна обеспечить возможности [6.1]:
быстрого создания и развертывания приложений, разработки приложений на основе открытых стандартов;работы в гетерогенной среде;включения в орбиту электронного бизнеса любых устройств, новых партнеров, поддержки новых языков и национальных стандартов при минимизации объема работ по изменению кодов и повторному развертыванию приложений.
Построение такой IT-инфраструктуры связано с деятельностью в трех направлениях:
интеграция (Integration): создание средств для взаимодействия и совместной работы персонала, унифицированного представления и взаимодействия рабочих процессов, доступа в реальном времени к распределенной и разнотипной информации;автоматизация (Automation): внедрение средств автоматизированного управления информационной инфраструктурой;виртуализация (Virtualization): применение эффективных современных методов размещения и использования информационных, вычислительных и других видов ресурсов информационных систем.
Интеграция должна обеспечить следующие возможности:
оперативного взаимодействия и совместного доступа к данным сотрудникам предприятия, поставщикам и клиентам;доступа к данным в любое время и с помощью любых средств (телефон, карманный компьютер и пр.);быстрой адаптации пользователей к изменениям в информационной системе (путем использования стандартных интерфейсов, порталов для доступа к приложениям и т.д.);взаимодействия приложений на основе использования общепринятых стандартов и открытых технологий;оперативной модернизации старых приложений и перестройки бизнес-процессов при изменениях в бизнесе;доступа к данным независимо от их источника, местоположения и платформы;консолидации данных.
Общая характеристика программного обеспечения IBM WebSphere
Совокупность программных продуктов IBM WebSphere создает платформу для электронного бизнеса, основанную на использовании возможностей Internet. Программная платформа WebSphere базируется на широко распространенных стандартах, таких как Java, XML, J2EE. Это позволяет легко интегрировать разнотипные IT-среды, оперативно адаптироваться к изменению задач бизнеса, упростить доступ внешних пользователей к ресурсам системы. Большинство программных продуктов IBM WebSphere поддерживает множество наиболее распространенных аппаратных платформ и операционных сред, включая IBM AIX, OS/2, OS/390, z/OS, OS/400, Sun Solaris, HP-UX, MS Windows NT, Linux.
В упрощенном виде структура семейства продуктов IBM WebSphere показана на рис. 6.3. Здесь выделены три группы программных продуктов, входящих в семейство IBM WebSphere: ядро системы (основные средства) и инструментальные средства (Foundation & Tools), бизнес-порталы (Business Portals) и средства бизнес-интеграции (Business Integration).

Рис. 6.3. Семейство продуктов IBM WebSphere
Программные средства Foundation & Tools (<Ядро системы и инструментальные средства>) служат для быстрого создания и развертывания приложений на базе Web-технологий. Основная функция средств поддержки электронного бизнеса - это ведение бизнес-процессов и транзакций через Web. Сервер приложений WebSphere Application Server и инструментальные средства разработки приложений WebSphere Studio и VisualAge предоставляют надежную и масштабируемую инфраструктуру для обработки транзакций и разработки приложений. Это ПО обеспечивает безопасность транзакций и открытое развертывание Web-служб. Оно упрощает разработку приложений, предоставляя пользователям открытую и всеобъемлющую среду разработки.
Программные средства IBM WebSphere Business Portals (бизнес-порталы) предоставляют пользователям единую точку для доступа к различным приложениям, информационным ресурсам, взаимодействия с процессами и людьми. Семейство включает средства построения порталов, позволяет создавать персонализированные порталы для сотрудников, бизнес-партнеров и клиентов.
Программные средства Business Integration (бизнес-интеграция) предназначены для интеграции приложений и автоматизации бизнес-процессов. ПО WebSphere Business Integration предоставляет возможности для моделирования и имитации процессов, объединения отдельных участков обработки данных, связи с заказчиками и партнерами, сквозного контроля бизнес-процессов и управления процессами для достижения оптимальной эффективности.
Семейство продуктов IBM Visual Age
Состав семейства Visual Age средств разработки приложений показан на рис. 6.4.
Семейство продуктов WebSphere Studio
WebSphere Studio представляет собой открытую среду разработки для создания, тестирования и развертывания динамических приложений. Продукт WebSphere Studio основан на открытых технологиях и создан на базе платформы Eclipse. Он обеспечивает гибкую интеграцию (схожую с технологией порталов) многоязычных, многоплатформенных инструментальных средств разработки приложений. Эти средства повышают производительность труда разработчиков, отдачу от капиталовложений и уровень общей окупаемости. WebSphere Studio поставляется в различных конфигурациях и с различными средствами расширения от компании IBM и ее партнеров.
WebSphere Studio Homepage Builder - средство создания Web-страниц начального уровня. С его помощью можно создавать и публиковать Web-узлы профессионального качества, не обладая знаниями HTML или навыками программирования. Это средство располагает интуитивным интерфейсом, удобными мастерами и шаблонами и поддержкой JavaScript, Dynamic HTML и Cascading Style Sheets.
WebSphere Studio Site Developer - надежная и удобная в использовании среда разработки, помогающая быстро создавать, тестировать и поддерживать динамические Web-узлы, приложения и Web-службы.
WebSphere Studio Application Developer представляет собой основную среду разработки приложений компании IBM для создания и сопровождения J2EE-приложений и Web-служб. Продукт разработан на базе последних новшеств в открытой универсальной платформе Eclipse и написан с учетом спецификаций J2EE.
WebSphere Studio Application Developer Integration Edition создан на базе функциональности, предлагаемой продуктом WebSphere Studio Application Developer. Он предоставляет интегрированную среду разработки следующего поколения для создания, тестирования, интеграции и развертывания J2EE-приложений и Web-служб, оптимизированную для использования совместно с WebSphere Application Server Enterprise.
WebSphere Studio Enterprise Developer поддерживает технологию J2EE, обеспечивает быструю разработку приложений (RAD - Rapid Application Development) и поддержку коллективов разработчиков корпоративных приложений. Помогает создавать, развертывать и поддерживать Web-приложения, традиционные приложения и связующие звенья между ними.
Семейство программных продуктов WebSphere Commerce
ПО WebSphere Commerce версии 5.4 представляет собой решение для продающей стороны в электронной коммерции, созданное для сред Business-to-Business (B2B) и Business-to-Consumer (B2C). Это гибкое и адаптируемое прикладное ПО состоит из набора интегрированных программных компонентов, которые позволяют создавать узлы электронной коммерции и управлять ими, а также создавать надежные среды электронной коммерции.
Программные продукты WebSphere Commerce созданы на базе основных технологических продуктов компании IBM, интегрированных в продукты WebSphere Commerce и поставляемые с ними в одном пакете. Сюда входят продукты WebSphere Application Server, IBM HTTP Server и DB2 Universal Database.
Выпускаются две версии WebSphere Commerce v 5.4. Версия Professional Edition отвечает нуждам большинства организаций типа B2C, а Business Edition является подходящей платформой для большинства окружений типа B2B и Business-to-Business-to-Consumer (продажи заказчикам через оптовых продавцов и торговых посредников). Основные продукты IBM WebSphere Commerce показаны на рис. 6.8.
WebSphere Commerce Professional Edition (WCPE) является сервером для поддержки коммерческой деятельности с широкими возможностями, отвечающими нуждам любой инициативы по розничным продажам и созданию витрин в режиме онлайн, начиная с простейших задач и заканчивая очень сложными узлами с персонифицированной рекламой, скидками, перекрестными продажами и использованием цифровых средств аудиовизуальной информации.
Поддерживаемые платформы: WINDOWS NT, WINDOWS 2000, LINUX, AIX, SUN.
WebSphere Commerce Business Edition (WCBE) предлагает дополнительные преимущества для организаций, которым необходимы удобные в реализации средства поддержки оперативной коммерческой деятельности для их использования вместе с заказчиками и партнерами. Эти преимущества реализуются через управление отношениями при торговле в режиме онлайн и основанную на стандартах интеграцию. Business Edition предоставляет функциональность, специфичную для коммерции Business-to-Business.
Основные возможности:
Использование технологии Lotus Sametime, обеспечивающей мгновенный обмен сообщениями в реальном времени, а также совместное использование приложений. Поддержка процедур выставления и ведения счетов, а также управления кредитами; Возможность устанавливать иерархию безопасного доступа к функциям. Поддержка заказов на покупки.Позволяет покупателям настраивать запрос на цены, то есть изменять, копировать, отменять, закрывать или пересылать его. Возможность совместной работы продавцов и покупателей в режиме онлайн - предоставление черновиков контрактов и шаблонов обсуждения предложений на основе Lotus QuickPlace.
WebSphere Commerce Professional Entry Edition является версией WCPE с ограниченной лицензией, предоставляющей коммерческое решение начального уровня для малого и среднего бизнеса. Это тот же самый продукт, что и WCPE, но со следующими ограничениями:
максимум один процессор, одно хранилище и один сервер на рабочую систему; ПО Sametime в комплект поставки не входит; поддержка только Windows NT или Windows 2000, DB2 Universal Database Enterprise Edition и IBM HTTP Server.
WebSphere Commerce Portal создан на базе продуктов WebSphere Portal и WebSphere Commerce. Этот продукт включает в себя все необходимые компоненты для создания интегрированного портала для электронной коммерции. Основные возможности:
индивидуализация для уникальных и специальных пользовательских профилей;предоставление заказчикам доступа к продуктам, рекламным акциям и другой статусной информации по всем торговым маркам и партнерам;интеграция операций внутри и между компаниями, приводящая к эффективному и быстрому управлению заказами.
Семейство программных продуктов WebSphere Portal
Стратегия IBM в области порталов состоит в том, чтобы предлагать организациям каркас порталов - программный продукт WebSphere Portal. Это предложение предназначено для построения порталов в масштабе предприятия. WebSphere Portal может быть развернут как корпоративный портал электронного бизнеса для сотрудников, бизнес-партнеров и заказчиков, поддерживающий полный объем функций систем взаимодействия <бизнес-сотрудник> (B2E), <бизнес-бизнес> (B2B) и <бизнес-потребитель> (B2C).
Портал - единый интерфейс, который предоставляет пользователю доступ ко всему, что ему необходимо, независимо от того, где находятся ресурсы, к которым он хочет получить доступ. Хочет ли пользователь найти и купить книгу, получить доступ к счету и перевести деньги или изменить персональную информацию - во всех случаях портал предоставит ему доступ ко всей необходимой информации в одном виртуальном месте. Единая точка доступа ко всем ресурсам уменьшает информационные перегрузки и увеличивает эффективность использования Web-сайта. Порталы предоставляют широкий диапазон различных возможностей, таких как поддержка безопасности, поиск, управление документацией, просмотр документации и т. д.
Один из вариантов архитектуры информационной системы с WebSphere Portal показан на рис. 6.9.

Рис. 6.9. Архитектура информационной системы с WebSphere Portal
Аналогично рабочему столу рабочей станции, портал отображает различную информацию и сервисы в едином интерфейсе. В отличие от рабочего стола, портал доступен пользователям с большого числа клиентских устройств.
Портлеты - основные программные элементы портала, предоставляющие доступ к приложениям, Web-контенту и другим ресурсам. Портлет - небольшое приложение, обычно представляемое окном на Web-странице.
Клиенты организации могут иметь различные информационные потребности. Соответственно, предусмотрены различные типы порталов. Эти типы могут быть разделены на три группы:
Business-to-Consumer (B2C) (бизнес-потребитель). Этот тип порталов применяется для предоставления пользователям доступа к таким информационным ресурсам, как инструкции по применению продукции, прайс-листы и т.
VisualAge C++
VisualAge C++ Professional для AIX представляет собой высокопродуктивную и мощную среду разработки для генерации и отладки программных приложений на языках С и С++ для OC AIX.
VisualAge COBOL
VisualAge COBOL для Windows NT - это мощный инструмент для разработки приложений на языке COBOL для среды Windows NT. Он использует популярный язык COBOL с объектно-ориентированными расширениями. В среду разработки приложений входят компилятор, библиотеки времени исполнения, визуальные средства создания приложений, отладчик, редактор, анализатор производительности, рабочая структура (Workframe) и вспомогательные средства. Возможности разработки и удаленного редактирования/компиляции/отладки этого ПО позволяют работать с серверными приложениями OS/390, не прибегая к удвоению ресурсов и управляя серверной средой с рабочей станции.
VisualAge Generator
IBM VisualAge Generator представляет собой среду быстрой разработки и развертывания приложений. VisualAge Generator обеспечивает обработку большого числа транзакций в многоуровневых и многоплатформенных окружениях электронного бизнеса и маскирует сложность данных и каналов связи. Разработчики с небольшим опытом работы с языком Java или даже совсем новички смогут внедрять сквозные Java-системы для электронного бизнеса. Разработчики на объектно-ориентированных языках и языке Java могут создавать системы, работающие на традиционных транзакционных платформах, таких как CICS, а также организовывать доступ к унаследованным данным.
VisualAge Smalltalk
С помощью объектно-ориентированного языка Smalltalk можно быстро создавать переносимые, масштабируемые и многоуровневые бизнес-приложения.
Благодаря поддержке Web-служб, VisualAge Smalltalk позволяет создавать автономные модульные приложения. С помощью таких стандартных промышленных протоколов, как протокол обмена сообщениями Simple Object Access Protocol (SOAP) и подключаемый модуль WebSphere Open Servlet Engine (OSE), код, написанный на языке Smalltalk, можно использовать в любом месте сети.
VisualAge Smalltalk позволяет программистам создавать и развертывать межплатформенные объектно-ориентированные приложения электронной коммерции.
WebSphere Application Server (Base)
WebSphere Application Server - следующий уровень инфраструктуры семейства WebSphere Application Servers. Данная версия предлагается для пользователей, которым нужен полный диапазон технологий J2EE 1.3, включая EJB и JMS.
WebSphere Application Server Enterprise
WebSphere Application Server Enterprise предоставляет все возможности и средства предыдущей версии, плюс к этому добавляет широкий диапазон программных модулей для разработки приложений, а также для взаимодействия с разнообразными источниками данных.
WebSphere Application Server - Express
Express - наиболее дешевая и легкая для использования версия WebSphere Application Servers. Данная версия предоставляет поддержку простых динамических web-сайтов, основанных на Java-сервлетах, страницах JSP, технологиях Web-сервисов. Express предоставляет возможность быстрого размещения Web-приложений, требуя при этом минимальных затрат на поддержку функционирования.
WebSphere Application Server for z/OS
WebSphere Application Server for z/OS разработан специально для платформы z/OS и использует преимущества, предоставляемые z/OS и zSeries.
Любая конфигурация WebSphere Application Servers включает определенный набор серверов и компонентов. В частности, конфигурация Enterprise включает компонент Process Choreographer (<Дирижер процессов>), поддерживающий приложения, использующие модели бизнес-процессов (этот компонент показан на рис. 6.4 пунктиром).
Процесс - это, как правило, многошаговая операция. Графически процессы представляются с помощью направленных (ориентированных) графов. Главными составными элементами этих графов являются операции и управляющие соединители. Операции описывают подлежащие исполнению задачи, а управляющие соединители - последовательность, в которой должны выполняться операции. На рис.6.6 показан пример графа процесса.

Рис. 6.6. Пример графического представления бизнес-процесса
Process Choreographer поддерживает следующие типы операций:
элементарные операции - для вызова процедур и служб;операции с участием человека;операции, связанные с наступлением (инициирующего) события (информация о событиях поступает в процесс через интерфейс API программы Process Choreographer);операции процесса (используются для построения вложенных процессов);пустые операции.

Рис. 6.7. Архитектура информационной системы с Edge Server
Прежде приложения содержали код для реализации отдельных бизнес-функций (например, код для функции <создание записи заказа>) и код для логики, определяющей последовательность выполнения функций приложения и соответствующей определенным бизнес-требованиям (например, такому требованию: <сообщения о крупных заказах должны утверждаться отдельно>). При изменении бизнес-требований необходимо было менять программный код. Применение технологий бизнес-процессов приводит к изменению способа создания приложений. Механизм процессов позволяет формировать архитектуру приложений, которая отделяет описание бизнес-логики (логики потока) от реализации бизнес-функций. Получившаяся в результате структура приложений была названа <приложения на основе бизнес-процессов>. Логика управления процессом реализуется через систему управления потоками операций, которая отвечает за вызов отдельных бизнес-функций в соответствии с бизнес-логикой.
Приложения на основе бизнес-процессов обладают определенными преимуществами по сравнению с традиционными приложениями, поскольку они характеризуются многими новыми свойствами, такими как параллелизм, способность к восстановлению, гетерогенное и распределенное выполнение.
WebSphere Application Server Network Deployment
Данная версия расширяет базовую конфигурацию, предоставляя широкий диапазон различных возможностей для поддержки распределенных конфигураций. Она предназначена для крупного бизнеса, где приложения разворачиваются для обслуживания большого количества клиентов.
WebSphere Application Servers
WebSphere Application Servers - набор серверов, которые поддерживают спецификацию J2EE. Это означает, что любые Web-приложения, соответствующие этой спецификации, могут быть размещены на любом из серверов семейства WebSphere Application Servers. Серверы приложений являются базой для развертывания других продуктов семейства WebSphere. Например, наличия сервера приложений требует продукт WebSphere Commerce.
В трехуровневой клиент-серверной архитектуре сервер приложений размещается между клиентом и базами данных и используется для реализации бизнес-логики (выполнения программного кода приложений) (рис.6.5).
WebSphere Application Servers доступны в различных конфигурациях и на различных платформах, в том числе на WINDOWS NT, WINDOWS 2000, AIX, SUN, LINUX, z/OS.

Рис. 6.5. Трехуровневая архитектура клиент-сервер
WebSphere Application Servers предоставляют следующие возможности:
Интегрированная поддержка для основных открытых стандартов Web-служб. Полная совместимость со стандартом J2EE 1.3, включая корпоративные средства JMS. Расширяемая инфраструктура с высоким уровнем безопасности.
Гибкость, обусловленная широкой межплатформенной поддержкой и наличием различных вариантов конфигурации на базе единого кода сервера приложений.
Высокая продуктивность благодаря интегрированной среде разработки, основанной на открытых стандартах. Возможности распределения рабочей нагрузки и кэширования для интеллектуальной оптимизации производительности. Единое администрирование через браузер во всех вариантах развертывания.Высокий уровень доступности приложений за счет разнообразных возможностей кластеризации и балансировки нагрузки.
WebSphere Application Servers доступны в разных конфигурациях. Это сделано для того, чтобы удовлетворить различные потребности бизнеса.
Конфигурации WebSphere Application Servers:
WebSphere Application Server - Express;WebSphere Application Server(Base);WebSphere Application Server Network Deployment;WebSphere Application Server Enterprise;WebSphere Application Server for z/OS.
Анализ данных с целью поддержки принятия решений (IBM DB2 Business Intelligence)
Программные средства, объединяемые названием IBM DB2 Business Intelligence (<деловой интеллект>), предназначены для анализа накопленных (исторических) данных с целью поддержки принятия решений. В настоящее время это направление является одним из наиболее приоритетных в сфере технологий управления данными. Это связано, с одной стороны, с тем, что использование исторических данных может помочь (и помогает) в поиске наилучших решений в деловой деятельности, а, с другой стороны, с возможностями организовать хранение, быстрый поиск необходимых данных и извлечение из них нужной информации (знаний) с помощью современных компьютерных средств.
Функционально программные средства этого направления делят на четыре группы:
средства анализа данных в реальном масштабе времени (OLAP-On-line Analytical Processing);средства cоздания хранилищ данных (Data Warehouse);средства поддержки доступа к данным;средства интеллектуальной обработки данных, или <добычи информации> (Intelligent Miner).
Анализ данных в реальном масштабе времени (OLAP) осуществляется c целью поддержки принятия решений (оперативных или стратегических) по управлению бизнесом. Информационные системы, поддерживающие этот вид деятельности, называют Системами поддержки принятия решений (СППР).
Термин OLAP был предложен в1993 году Эдвардом Коддом (Э. Кодд - автор реляционной модели данных). По Кодду, OLAP - это технология комплексного динамического синтеза, анализа и консолидации больших объемов многомерных данных. Существует так называемый <тест FASMI>, содержащий основные принципы OLAP-технологий:
Fast (быстрый) - предоставление результатов анализа за приемлемое время (обычно не более пяти секунд);Analysis (анализ) - возможность проведения любого логического и статистического анализа данных, а также сохранения его результатов в доступном для пользователя виде;Shared (разделяемый) - многопользовательский доступ к данным с поддержкой механизмов блокировок и авторизованного доступа;Multidimensional (многомерный) - многомерное представление данных на концептуальном уровне, включая полную поддержку иерархий и множественных иерархий;Information (информации) - возможность обращаться к любой нужной информации независимо от ее объема и места хранения.
Для того чтобы удовлетворить требования относительно времени анализа данных и получения ответа на сложные запросы, понадобилось задействовать новую технологию организации и хранения данных. Эта новая технология получила название <хранилище данных> (Data Warehouse).
Хранилище данных. Согласно определению автора концепции хранилища данных Б. Инмона [6.8]), это <предметно-ориентированные, интегрированные, неизменчивые, поддерживающие хронологию наборы данных, организованные для целей поддержки принятия решений>. В этом определении под интеграцией данных понимается объединение и согласованное представление данных из различных источников. <Поддержка хронологии> означает наличие <исторических> данных, т.е. данных, соответствующих интервалу времени, предшествующему текущему моменту. <Неизменчивость данных> означает, что изменение данных в хранилище осуществляется путем добавления новых данных, соответствующих определенному временному интервалу, без изменения информации, уже находящейся в хранилище.
К основным требованиям, предъявляемым к хранилищам данных, относятся:
поддержка высокой скорости получения данных из хранилища (т.е. малого времени реакции на запросы);поддержка внутренней непротиворечивости данных;возможность получения срезов данных (например, значений совокупности показателей за определенный период, значение одного показателя за ряд последовательных временных интервалов и т.д.);наличие удобных средств для просмотра данных в хранилище;полнота и достоверность хранимых данных.
Хранилище данных - это единый источник данных, относящихся к функционированию отрасли, предприятия, организации, содержащий всю необходимую и достоверную информацию для поддержки принятия решений.
Типичное хранилище, как правило, отличается от обычной реляционной базы данных. Поясним это утверждение путем рассмотрения логических моделей реляционной базы данных и данных хранилища.
В традиционных базах данных реляционного типа логическая модель данных - это совокупность двумерных (плоских) таблиц, построенных так, чтобы обеспечить возможность наиболее эффективного выполнения различных операций с данными.
Надо отметить, что измерения многомерного куба могут иметь иерархическую структуру. Например, измерение <пункт отправки> может быть представлено трехуровневой иерархической схемой (см. рис. 6.16.).
В отличие от нормализованной логической модели базы данных реляционного типа, логическая модель типа куба допускает избыточность данных, т.е. содержит помимо исходных данных и некоторые заранее вычисленные итоговые данные (агрегированные данные). Это оправдано в СППР, т.к. позволяет уменьшить время реакции системы на сложные запросы.

Рис. 6.16. Иерархическая схема измерения "пункт отправки"
Мы рассмотрели логическую модель хранилища, представляющую данные в виде совокупности многомерных кубов. Физическая реализация хранилища обычно осуществляется одним из следующих способов [6.8]:
с использованием специализированных многомерных структур, отличающихся от традиционных реляционных баз данных;с использованием для хранения данных реляционных баз данных;гибридное решение: детальные данные хранятся в базах реляционного типа, а агрегированные - в специальных многомерных структурах.
В IBM DB2 OLAP Server поддерживается многомерная модель данных на основе реляционной СУБД DB2 UDB. Средства повышения производительности (см. раздел 6.3.2) позволяют обеспечить требуемые временные характеристики.
Инструменты для создания хранилищ данных позволяют собирать данные из систем управления предприятием и внешних источников, <очищать> их, преобразовывать и загружать в хранилище данных.
На этапе проектирования в распоряжение пользователя предоставляется набор управляемых инструментов для создания хранилищ данных. В его состав входят инструменты, которые позволяют генерировать различные схемы очистки и загрузки данных, а также графически описывать действия, необходимые для построения и сопровождения хранилища данных. Основной программный продукт этой группы - IBM DB2 Warehouse Manager; его назначение, функции и особенности приведены в таблице 6.3.
Средства поддержки доступа к данным представляют собой API и серверы промежуточного ПО, которые поддерживают доступ клиентских инструментов к бизнес-информации, а также обработку этой информации. Связующие программные серверы позволяют клиентам получать прозрачный доступ к многочисленным серверам баз данных (созданным как IBM, так и другими разработчиками). Основные программные продукты этой группы описаны в таблице 6.3.
Средства интеллектуальной обработки данных (<добычи информации>, Intelligent Miner). Основное назначение интеллектуальной обработки данных (ИАД) - поиск в данных скрытых закономерностей. Большинство методов ИАД первоначально разрабатывалось в рамках направления исследований, которое получило название <системы искусственного интеллекта>. Только сейчас, когда образовались большие и быстро растущие массивы корпоративных данных, эти методы оказались в полной мере востребованными.
Сфера поиска закономерностей отличается от оперативной аналитической обработки данных (OLAP) тем, что накопленные сведения в ней автоматически обобщаются до информации, которая может быть охарактеризована как знания. Этот процесс чрезвычайно актуален сейчас, и важность его будет со временем только расти. Как утверждают специалисты, количество информации в мире удваивается каждые 20 месяцев, в то время как компьютерные технологии, обещавшие фонтан мудрости, пока что только регулируют потоки данных.
Интеллектуальный анализ данных определяется в большинстве публикаций как извлечение <зерен знаний из гор данных>. При этом в английском языке существует два термина, переводимые как ИАД, - Knowledge Discovery in Databases (KDD) и Data Mining (DM). В большинстве работ они используются как синонимы.
Покажем на примерах различие задач <оперативной аналитической обработки данных> (OLAP) и <интеллектуального анализа данных> (ИАД). Если задачей OLAP является, например, ответ на вопрос <как изменились эксплуатационные затраты путевого хозяйства Московской железной дороги в период с 1998 по 2002 год?>, то цель ИАД - ответить на вопросы: <какие факторы в наибольшей степени влияют на эксплуатационные расходы путевого хозяйства Московской железной дороги?>, <каковы ожидаемые величины эксплуатационных расходов в 2003 году?> и т.д.
Подобно ассоциациям, последовательности определяют связь между событиями, но наступающими не одновременно, а с некоторым разрывом во времени. Мерой взаимосвязи между последовательными событиями А, В, С могут быть условные вероятности события В при условии, что событие А произошло, и условная вероятность события С при условии, что А и В имели место.Прогнозирование. Это задача оценки будущих значений показателя на основе анализа текущих и исторических данных. Например, может быть сделан прогноз объема перевозок, который ожидается в следующем году, на основе данных, накопленных в базе производственно-экономических показателей работы железной дороги. В задачах подобного типа чаще всего используются традиционные методы математической статистики.
DB2 Intelligent Miner - это набор продуктов, который предоставляет в распоряжение пользователя аналитические инструменты, необходимые для принятия продуманных и качественных бизнес-решений. Задачи, решаемые этим набором продуктов, могут привести к выбору более точной маркетинговой стратегии, к уменьшению оттока заказчиков, к увеличению прибыли от торговли через Internet. Основные продукты семейства DB2 Intelligent Miner описаны в таблице 6.3.
Нормализованная логическая модель базы данных реляционного типа характеризуется, в частности, следующими особенностями:
все значения, хранимые в ячейках таблиц (значения атрибутов), атомарны (т.е. в каждой ячейке таблицы располагается только одно значение);данные не дублируются (т.е. в базе данных отсутствует избыточность).

Рис. 6.14. Пример куба, содержащего данные об объемах перевозок грузов
Такое представление данных не всегда соответствует целям поддержки принятия решений, когда возникает необходимость быстрого получения ответов на сложные аналитические запросы. Более адекватной здесь является логическая модель данных в виде многомерного куба [6.8]. Куб - это геометрическая фигура с тремя измерениями. Кубы данных на практике имеют от 4 до 12 измерений; в этих случаях их называют гиперкубами. Измерение в кубе - это одна из характеристик данных. Например, в кубе, показанном на рис. 6.14, измерениями являются <время> (2001 г., 2002 г.), <пункт назначения> (Москва, Санкт-Петербург), <груз> (бензин, уголь). В ячейках куба (рис. 6.14) хранятся данные об объемах перевозок. Эти данные агрегированы по другим измерениям. Например, для куба на рис.6.14, если существует измерение <пункт отправки>, то приведенные на рисунке данные следует рассматривать как агрегированные по этому измерению (т.е. <1000> это есть общая масса угля, завезенного в Москву в 2001 году от всех поставщиков). На многомерном кубе легко определить множество операций, типичных при аналитической работе: сокращение числа измерений (проекции), слияние (объединение кубов, имеющих общие измерения) и т.д. Например, при агрегировании по измерению <груз> куб на рис. 6.14 превращается в квадрат, показанный на рис. 6.15.

Рис. 6.15. Агрегирование куба рис. 6.3.4 по измерению "груз"
Логическая модель хранилища при этом представляется множеством многомерных кубов (гиперкубов), в общем случае, с различными размерностями, каждый из которых соответствует одному или нескольким количественным показателям отрасли, организации, предприятия.
Таблица 6.3. Компоненты IBM Business Intelligence№ п/пОсновное назначениеПродуктФункциональность и особенности
| 1. | Анализ данных в реальном масштабе времени (OLAP) | IBM DB2 OLAP Server | поддержка многомерной модели данных (на базе реляционной СУБД); поддержка операции многомерной агрегации данных в различных иерархических структурах;параллельная обработка запросов;использование методов оптимизации запросов |
| 2. | Создание хранилищ данных (Data Warehouse) | IBM DB2 Warehouse Manager | расширение функциональности DB2 по извлечению, преобразованию и загрузке данных (ELT - Extraction, Transformation and Loading);поддержка управления метаданными и информационными каталогами (репозитариями);поддержка средств QMF for Windows (создание запросов для DB2 с помощью Windows или Web-интерфейса);поддержка применения <агентов>, осуществляющих перемещение данных между исходной и целевой системами без участия центрального сервера |
| 3. | Поддержка доступа к данным | Query Management Facility (QMF) | создание отчетов и запросов к базе данных;создание запросов на языке Java для их инициализации через браузер;интеграция результатов выполнения запросов с электронными таблицами и персональными базами данных;использование методов синтаксического анализа запросов на SQL;контроль потребления ресурсов группами пользователей |
| DB2 Warehouse Manager Connector for SAP R/3 | доступ и перенос бизнес-объектов SAP в хранилище DB2;извлечение умеренных объемов данных SAP R3 | ||
| D2 Warehouse Manager Connector to the Web | извлечение данных из базы данных WSA ( IBM WebSphere Site Analyser) или витрин данных и размещение их в хранилище;проверка выполнения продуктом WSA копирования данных о Web-трафике в целевое хранилище | ||
| DB2 Warehouse Manager Sourcing Agent for z/OS | программа-агент, предоставляющая возможность для IBM DB2 Warehouse Manager, работающего под Linux, UNIX или Windows, осуществлять извлечение и преобразование данных, размещенных на платформе z/OS | ||
| 4. | Интеллектуальная обработка данных (Intelligence Miner) | DB2 Intelligent Miner Modeling | обнаружение ассоциаций;кластеризация;классификация;совместимость с языком Predective Model Markup Language (PMML), версия 2.0 |
| DB2 Intelligent Miner Visualizer | графическое представление результатов решения задач обнаружения ассоциаций, кластеризации и классификации;поддержка языка PMML, версия 2.0 | ||
| DB2 Intelligent Miner Scoring | встраивание моделей (результатов интеллектуальной обработки, полученных с помощью DB2 Intelligent Miner Modeling) в приложения для использования с новыми данными | ||
| DB2 Intelligent Miner for Text | извлечение, индексирование, анализ и классификация информации из текстовых источников (документы, Web-страницы, бланки) |
Первоначально средства ИАД разрабатывались так, что в качестве исходного материала для анализа принимались данные, организованные в плоские реляционные таблицы. Применение ИАД к данным, представленным с помощью хранилищ в виде гиперкуба, во многих случаях может оказаться более эффективным.
Обычно выделяют следующие пять типов задач ИАД [6.9]:
Классификация. Наиболее распространенная задача ИАД. Она позволяет выявить признаки, характеризующие однотипные группы объектов - классы, для того, чтобы по известным значениям этих признаков можно было отнести новый объект к тому или иному классу. Ключевым моментом решения этой задачи является анализ множества заранее классифицированных объектов. Наиболее типичный пример использования классификации - конкурентная борьба между поставщиками товаров и услуг за определенные группы клиентов. Классификация может помочь определить характеристики неустойчивых клиентов, склонных перейти к другому поставщику, что позволяет найти оптимальный способ удержать их от этого шага (например, посредством предоставления скидок, льгот или даже с помощью индивидуальной работы с представителями <групп риска>).Кластеризация. Логически продолжает идею классификации на более сложный случай, когда сами классы не предопределены, т.е. неизвестна принадлежность заданных объектов тому или иному классу. Результатом использования метода, выполняющего кластеризацию, как раз является вариант разбиения множества объектов на группы, включающие <близкие> объекты. Так, можно выделить родственные группы клиентов или покупателей с тем, чтобы вести в их отношении дифференцированную политику. В приведенном выше примере <группа риска> - категории клиентов, готовых уйти к другому поставщику - средствами кластеризации может быть выявлена до начала процесса ухода, что позволит принимать профилактические, а не экстренные меры. Выявление ассоциаций. Ассоциация - это связь между двумя или несколькими одновременно наступающими событиями. Количественной мерой ассоциации может быть, например, условная вероятность события А при условии, что событие В произошло.Выявление последовательностей.
Интеграция информации (IBM DB2 Information Integration)
Информационная интеграция - это набор технологий, которые позволяют использовать при решении прикладных задач данные различного типа (структурированные, неструктурированные) вне зависимости от места их размещения, полученные с помощью запросов на языке SQL или XML, а также с помощью Web-служб.
Интеграция обеспечивает:
объединение данных, полученных от разных источников (базы данных, Web-службы, хранилища);создание моделей данных и интерфейсов;доступ к разнообразным типам данных;преобразование данных в требуемый формат.
Обычно рассматривают три функции интеграции: объединение данных, перемещение данных (репликация), преобразование данных (конвертация) (см. рис. 6.17).

Рис. 6.17. Основные функции интеграции
Объединение позволяет предоставить доступ к данным от большого числа различных источников и платформ так, как если бы эти данные принадлежали единому ресурсу.
Возможности систем объединения:
данные можно хранить в исходных системах, не перемещая их в единую систему хранения;можно использовать единый API для поиска и преобразования данных;объединенная система скрывает любые различия в местоположении, диалектах сети, топологии данных;можно получить доступ к хранилищам данных либо непосредственно, либо путем запроса, который возвращает данные динамически, что позволяет осуществлять управление данными с помощью единого диалекта SQL.
Объединение имеет смысл использовать, когда технические требования проекта информационной системы предполагают многократный поиск, вставку, обновление и удаление данных из разнородных источников.
Репликация - это процесс дублирования и размещения в результирующем ресурсе данных из различных источников. В зависимости от требований архитектуры информационной системы предприятия можно использовать различные схемы дублирования и размещения данных.
Репликация предоставляет следующие возможности:
автоматизированное и надежное перемещение изменений данных из одной системы в другую (позволяет автоматически вносить изменения при появлении их в источнике);создание идентичных копий в двух системах (например, поддержка второй копии данных для их восстановления);копирование подмножества данных из одной системы во многие (например, с целью синхронизации информации в разных системах).
Такой вид репликации называется распределением данных;копирование выбранных данных из многих источников в один (например, чтобы объединить информацию в информационное хранилище). Такой вид репликации называется консолидацией данных.
Репликация поддерживает целостность данных.
Конвертация данных - формирование документов на основе оптимизированных SQL-запросов к различным источникам данных. Преобразование данных может осуществляться как в момент их перемещения, так и при создании представлений.
Оптимизация SQL-запросов избавляет программиста от необходимости рассматривать особенности фактических источников данных при написании прикладной программы. Оптимизация позволяет приспособиться к факторам, которые не могли быть известны при написании программы, а также при ее изменении в связи с изменениями среды окружения.
При использовании информационной интеграции можно работать с данными, которые находятся как внутри информационной системы предприятия, так и за ее пределами.
Семейство IBM DB2 Information Integration состоит из двух продуктов: IBM DB2 Information Integration и IBM DB2 Information Integration for Content. Первый продукт (IBM DB2 Information Integration) предназначен для применения в тех случаях, когда основными источниками информации для работы приложений, использующих SQL, являются реляционные базы данных, дополненные нереляционными источниками (документы XML, Web-службы и др.).
Продукт IBM DB2 Information Integration for Content предназначен для случаев, когда приложениям необходима интеграция гетерогенной информации. Этот продукт очень подойдет тем разработчикам решений по управлению информационным наполнением, которые знакомы с программными интерфейсами управления контентом и объектно-ориентированным программированием.
Информация по функциям и поддерживаемым форматам данных семейства IBM DB2 Information Integration представлена в таблице 6.4.
| 1. | Объединение данных | Возможность доступа к гетерогенным данным, хранящимся в исходных системах, без их перемещения в единую систему хранения.Использование языка SQL и процедур оптимизации запросов.Единый интерфейс для поиска и преобразования данных. | Реляционные источники: DB2, Informix Dynamic Server, Informix Extended Parallel Server, Microsoft SQL Server, ORACLE, Sysbase SQL Server, Sysbase Adaptive Server Enterprise, Teradata; источники, доступные с помощью ODBC. Нереляционные источники: Excel, Documentum Enterprise Content; источники данных, доступные с помощью IBM Lotus Extended Search, IBM DB2 Information Integrator for Content |
| 2. | Репликация данных | Автоматический перенос изменений данных из одной системы в другую.Поддержка идентичных копий.Копирование подмножества данных из одной системы во многие (распределение данных).Копирование подмножеств данных из многих источников в один (консолидация данных).Автоматизация перемещения данных (по графику, в зависимости от событий и т.д.). | DB2, Informix Dynamic Server, Microsoft SQL Server, ORACLE, Sysbase SQL Server, Sysbase Adaptive Server Enterprise, Informix Extended Parallel Server, Teradata; источники, доступные с помощью ODBC |
| 3. | Конвертация данных | Создание и публикация XML-документов с использованием разнообразных источников данных.Использование языка SQL с процедурами оптимизации доступа к данным.Возможность использования Web-сервисов для конвертации данных. | Реляционные источники (те же, что в п.1). Нереляционные источники: Очереди сообщений IBM WebSphere MQ; Web-службы; Excel; XML-документы; Documentum Enterprise Content Management System; источники данных доступные с помощью IBM Lotus Extended Search; каталоги LDAP; источники IBM DB2 Information Integrator for Content (IBM DB2 Content Manager и др.) |
Серверы баз данных DB2 UDB: основные особенности
DB2 UDB - это объектно-реляционная база данных, обладающая высокими показателями масштабируемости, расширяемости, простоты работы и управления.
Рассмотрим основные особенности DB2 UDB[6.6].
Масштабируемость - это возможность использовать один и тот же продукт (версии одного продукта) для задач различной сложности (например, для управления данными в масштабе отдела и в масштабе предприятия) с сохранением всей функциональности.
Масштабируемость в DB2 обеспечивается:
расширенной параллельной обработкой;высокопроизводительной обработкой данных;эффективной работой с крупными базами данных.
В DB2 Universal Database параллельная обработка данных используется как для ускорения обработки транзакций, так и для ускорения обработки сложных запросов, а также для смешанных задач, включающих оба типа обработки. База данных поддерживает и параллельную обработку транзакций, и параллельную обработку сложных запросов на всех основных архитектурах аппаратных средств, включая симметричные мультипроцессорные системы (SMP), кластеры и системы с массовым параллелизмом (МРР) (рис. 6.12).

Рис. 6.12. Архитектуры аппаратных средств, поддерживаемые DB2 UDB
Параллельная обработка на SMP означает, что на машине с SMP UDB будет одновременно выполнять несколько транзакций (операторов SQL) параллельно, автоматически распределяя их между процессорами. Кроме того, UDB может выполнить параллельную обработку одного запроса (оператора SQL), разбивая его на подзадачи и направляя каждую подзадачу на свой процессор. Более того, если данные для оператора SQL распределены на нескольких дисковых подсистемах, то для параллельного извлечения данных в UDB будут использоваться функции параллельного ввода/вывода.
Поддержка кластеров и систем с массовым параллелизмом MPP означает, что база данных UDB может быть размещена на нескольких серверах в кластере или на нескольких узлах в системе с массовым параллелизмом. Несколько транзакций (операторов SQL) будут выполняться параллельно за счет автоматического распределения между несколькими узлами.
Кроме того, UDB может выполнить параллельную обработку одного запроса (оператора SQL), разбивая его на подзадачи и направляя каждую подзадачу на отдельный узел. Основой эффективных средств параллельной обработки с использованием нескольких узлов является интеллектуальное разделение и параллельная оптимизация. UDB автоматически разделяет (распределяет) данные между несколькими узлами, причем оптимизатор передает обработку тому узлу, на котором находятся нужные данные, сокращая до минимума пересылку данных между узлами.
Помимо расширенной параллельной обработки DB2 UDB, так же, как ряд других современных баз данных, поддерживает другие важные функции высокопроизводительной обработки данных, которые значительно повышают производительность как обработки сложных запросов, так и обработки транзакций. Благодаря этим и прочим функциональным возможностям DB2 UDB особенно хорошо подходит для работы со смешанными задачами (в которых имеют место и транзакционная обработка, и обработка сложных запросов).
К средствам повышения производительности следует также отнести:
Поддержку 64-разрядной памяти. В настоящее время в системе дополнительно реализована поддержка очень больших объемов физической памяти (64-разрядной). В DB2 применяются 64-разрядные и 32-разрядные системы, позволяющие работать более чем с 4 Гбайт физической памяти. С помощью буферного пула в этой дополнительной памяти можно хранить используемые в настоящий момент данные, благодаря чему значительно сокращается количество операций ввода/вывода и повышается производительность;Асинхронная очистка страниц. Возможность переложить операции записи буферизованных страниц с задачи выполнения запроса SQL на другую задачу позволяет значительно сократить время отклика системы на запросы. Задачи асинхронной очистки страниц обеспечивают наличие достаточного свободного пространства в буферах базы данных для обработки данных запроса. Эта функция позволяет при обработке запроса избежать ожидания синхронной записи модифицированных страниц из буфера на диск для освобождения места под данные запроса;Расположение табличных областей на нескольких носителях.
Кроме того, с ее помощью можно создавать индексы и собирать статистические данные в процессе загрузки. Утилита LOAD может значительно сократить время, необходимое для обновления или добавления данных;в DB2 UDB архитектура симметричных мультипроцессорных систем (SMP) применяется не только при обработке транзакций и запросов, но и при работе с утилитами. Это обеспечивает возможность параллельной загрузки данных, параллельного создания индексов, параллельного резервного копирования и восстановления;при работе с утилитами в DB2 UDB могут использоваться преимущества кластерных архитектур и архитектур с массовым параллелизмом. Основой для работы систем с массовым параллелизмом является интеллектуальное разделение. Данные перед загрузкой можно разбить на разделы. После этого их можно загружать параллельно на нескольких узлах, что значительно сокращает общее время процесса загрузки. После разделения данных утилиту LOAD можно запустить параллельно на всех узлах. Параллельно на всех узлах системы может выполняться команда создания индекса CREATE INDEX. Аналогично операции резервного копирования и восстановления также могут выполняться на нескольких узлах параллельно.
Благодаря всем этим расширенным функциям параллельной обработки, средствам высокопроизводительной обработки и возможностям эффективной работы с крупными базами данных DB2 Universal Database является наиболее масштабируемой объектно-реляционной базой данных с поддержкой Web.
Расширяемость - это возможность управлять не только данными, организованными с помощью реляционных таблиц с символами и числами, но и мультимедийными данными, комплексными объектами, такими как изображения, аудио, видео, пространственные данные, временные ряды и т.д. В эту категорию могут входить и такие объекты, как рентгеновские снимки, отпечатки пальцев, конструкторские чертежи и т.д. Технологии хранения таких данных в СУБД реляционного типа называют объектно-реляционными. Объектно-реляционные возможности позволяют добавлять к базе данных собственные типы данных, настраивая базу на конкретные требования.
Большие двоичные объекты можно использовать для хранения мультимедийных данных, таких как документы, видео, изображения и речь. Кроме того, большие объекты можно использовать для хранения некрупных структур, семантика которых задана с помощью пользовательских типов UDT и пользовательских функций UDF. Для больших объектов LOB имеется мощный набор встроенных функций для выполнения поиска, выделения подстроки и конкатенации. С помощью UDF в любое время можно определить дополнительные функции. Таблица может содержать несколько столбцов с большими объектами LOB (см. рис. 6.13).
Рис. 6.13. Хранение больших объектов (LOB)
Определяемые пользователем табличные функции (Table UDF) - пользователи могут теперь обращаться средствами SQL к данным, хранящимся не в реляционном формате, и при этом в полной мере использовать все возможности построения запросов реляционной базы данных. Часто возникают трудности, если невозможно включить данные из нереляционных источников в реляционную обработку. Определяемые пользователем табличные функции представляют собой расширение SQL, позволяющее решить эту проблему. Табличная функция представляет собой внешнюю определяемую пользователем функцию, которая создает производную таблицу. Программа этой функции может включать в себя обращение к данным из различных источников и преобразование их в табличную форму, возвращаемую этой табличной функцией. После создания табличной функции ее можно использовать в операторах FROM запросов.
Путем расширения деловых правил обеспечивается целостность хранящихся в базе данных. Эти правила дополнительно расширяют прочие объектно-ориентированные функции. С их помощью можно расширить существующие только в виде кода объектные библиотеки (методы которых изменить невозможно) для поддержки дополнительных атрибутов объектов и проверки ограничений. Ключевые возможности деловых правил включают в себя:
значения по умолчанию - позволяют устанавливать значения по умолчанию для тех строк, которым в операторах INSERT непосредственных значений не присваивается;проверка ограничений - используется для введения деловых правил, которые невозможно реализовать с помощью ограничений на уникальность ключей или ссылочной целостности.
Расширения DB2 Extenders строятся на основе объектно- реляционной инфраструктуры DB2. Каждое расширение представляет собой набор предопределенных пользовательских типов данных UDT, пользовательских функций UDF, триггеров, ограничений и хранимых процедур, решающих задачи конкретной прикладной области. С помощью расширений пользователи могут хранить в таблицах DB2 текстовые документы, изображения, видео- и аудиоролики путем добавления столбцов с новыми типами данных, определенными в расширении. Сами данные могут храниться как внутри таблицы, так и вне ее во внешних файлах. Кроме того, эти новые типы данных имеют атрибуты, описывающие различные аспекты их внутренней структуры, такие как, например, <язык> и <формат> для текстовых данных. Каждое расширение включает в себя необходимые функции для создания, обновления, удаления и поиска данных с новыми типами, определенными в расширении. Пользователи могут включать эти новые типы данных и функции в операторы SQL, обеспечивая интегрированный поиск по содержимому для всех типов данных.
В таблице 6.1 приведены основные компоненты IBM DB2 UDB, указано их назначение и основная функциональность.
Таблица 6.1. Компоненты IBM DB2 UDB№ п/п Название компонентаНазначение Основная функциональность
| 1. | DB2 XML Extender | Обеспечение работы с XML-документами | сохранение XML-документов;разработка XML-документов;преобразование данных в XML-документ;текстовый поиск в XML-документе (с использованием DB2 Text Extender) |
| 2. | DB2 Net Search Extender | Текстовый поиск в Internet из базы данных | Высокоскоростной и масштабируемый текстовый поиск в Internet из базы данных |
| 3. | DB2 OLAP Starter Kit | Поддержка онлайновых аналитических процедур (в отсутствие OLAP-сервера) | Создание сложных аналитических приложений (при отсутствии OLAP-сервера) |
| 4. | DB2 UDB2 Text Information Extender | Поиск по текстовым документам | быстрый поиск по текстовым документам на основе SQL-запросов;поддержка форматов HTML и XML;объединение в одном продукте функций DB2 Text Extender и DB2 Net Search Extender |
| 5. | DB2 Spatial Extender | Обработка пространственных данных | Хранение, доступ, управление и выполнение операций анализа пространственных данных в той же базе, где хранятся бизнес-данные и осуществляется визуализация результатов запросов |
| 6. | DB2 Data Links Manager | Управление внешними данными (находящимися за пределами базы данных) | доступ к внешним данным, находящимся в файлах внешней операционной системы, HTML, XML и изображениях;управление внешними данными (доступ, резервирование, восстановление);контроль целостности внешних данных |
| 7. | DB2 Relational Content | Доступ к базам данных ORACLE | повышение производительности при чтении баз данных ORACLE (при совместном использовании приложением DB2 и ORACLE);поддержка приложений и масштабируемой коммуникационной инфраструктуры для работы Web-приложений, приложений для Windows, UNIX, Linux и OS/2 с данными S/390 и AS/400 |
| 8. | DB2 Audio Extender | Работа с аудио-информацией | импорт и экспорт аудиофрагментов и атрибутов аудио-информации;защита и восстановление аудиоданных;поиск и проигрывание аудиофрагментов;поддержка широкого диапазона форматов аудиофайлов (WAVE, MIDI, MPEG 1, AU), работа с различными аудиосерверами |
| 9. | DB2 Image Extender | Работа с изображениями | импорт и экспорт изображений и их атрибутов;контроль доступа и преобразование форматов изображений;защита и восстановление изображений;поиск и просмотр изображений;создание уменьшенных версий изображений |
| 10. | DB2 Video Extender | Обработка видеоинформации | импорт и экспорт видеофрагментов и их атрибутов;защита и восстановление видеоданных;поиск и проигрывание видеофрагментов;раскадровка видеоданных (выявление точек <смены сцены>, в которых имеет место существенное различие между двумя следующими друг за другом кадрами, запись соответствующих данных и репрезентативных кадров);поддержка широкого спектра форматов видеофайлов, включая MPEG1, MPEG2, AVI, QuickTime;работа с различными видеосерверами |
В UDB администраторы базы данных могут разделить базу данных на части, называемые табличными областями (tablespaces). При создании таблицы можно определить имена базовой (base), индексной (index) и длинной (long) табличной области. Использование индексных и длинных табличных областей позволяет хранить индексы и большие объекты (LOB) отдельно от остальных табличных данных. Благодаря такой гибкости повышается производительность и готовность базы данных. Табличные области могут охватывать одно или несколько физических запоминающих устройств, то есть располагаться на нескольких носителях;Непосредственный доступ к носителям (работа с устройствами напрямую). UDB позволяет непосредственно работать с данными на устройстве, не тратя ресурсы на использование файловой системы, что повышает производительность базы данных. Администратор имеет возможность определить для табличной области режим непосредственной работы с устройством или использовать обычную файловую систему полностью совместимым с предыдущими версиями методом;Чтение больших блоков. Данная функция позволяет считывать несколько дисковых страниц за одну операцию ввода/вывода, что уменьшает нагрузку на центральный процессор и, соответственно, сокращает время отклика.
Масштабируемость включает в себя гораздо больше, нежели просто ускорение обработки транзакций и сложных запросов за счет параллельной обработки или других средств повышения производительности. Масштабируемыми должны быть и обслуживающие операции, такие как загрузка данных, резервное копирование и восстановление, генерация индексов. В DB2 UDB это достигается с помощью следующих средств:
DB2 UDB включает высокоскоростную утилиту загрузки LOAD, с помощью которой можно значительно повысить скорость загрузки данных, обеспечив при этом их восстанавливаемость. Эта утилита может принимать данные в различных файловых форматах и непосредственно создавать страницы табличных областей, не затрачивая ресурсы на работу с контрольным журналом и обработку операторов SQL INSERT.
Расширения в DB2 UDB можно разделить на три группы:
использование сложных типов данных;расширение деловых правил;расширение SQL;расширения DB2 Extenders.
К сложным типам данных относятся определяемые пользователем типы данных, определяемые пользователем функции, большие объекты.
Определяемые пользователем типы данных (UDT). С их помощью пользователи могут создавать новые типы данных, которые будут представлены в базе данных с использованием встроенных типов. Например, пользователь может определить два типа данных для валют: CDOLLAR для канадских долларов и USDOLLAR - для долларов США. Эти типы будут различаться в том смысле, что их невозможно будет непосредственно сравнивать друг с другом или с десятичным (decimal) типом, хотя именно десятичный тип может быть выбран для внутреннего представления этих двух типов данных в DB2. Определяемые пользователем типы данных, как и встроенные типы, могут применяться в качестве столбцов таблиц или параметров функций, включая определяемые пользователем функции (User-Defined Functions, UDF). Например, пользователь может определить тип данных ANGLE (угол, значения которого могут находиться в пределах от 1 до 360) и создать собственные функции для работы с этим типом, такие как SINE (вычисление синуса), COSINE (вычисление косинуса) и TANGENT (вычисление тангенса).
Определяемые пользователем функции (UDF). С их помощью в запросы можно включать мощные вычислительные предикаты и предикаты поиска для фильтрации данных непосредственно у их источника. Благодаря UDF пользователи могут создавать наборы функций для работы с пользовательскими типами данных, определив таким образом семантику этих типов. Поддержка UDF позволяет создавать библиотеки функций, причем их разработкой может заниматься IBM, независимые поставщики или сами заказчики, и затем встраивать их непосредственно в базу данных.
Большие объекты (LOB). С помощью больших объектов (LOB) пользователи могут хранить в базе данных очень крупные двоичные или текстовые объекты (размером в несколько гигабайт).
Например, пользователь может ввести ограничение на таблицу данных о служащих EMPLOYEE, чтобы должность сотрудника могла принимать только одно из значений 'Sales', 'Mqr', или 'Clerk' и чтобы заработная плата сотрудника, проработавшего в компании более 8 лет, составляла более 40 000 долларов;ссылочная целостность - позволяет устанавливать необходимые взаимосвязи между таблицами и внутри таблиц. Ссылочные ограничения объявляются при создании таблицы и обеспечивают согласованность значений данных между связанными столбцами различных таблиц. DB2 автоматически будет поддерживать эти взаимосвязи, так что разработчикам не придется программировать соответствующие функции в приложении;триггеры - можно использовать для реализации комплексных межтабличных деловых правил, автоматической генерации значений для новой добавленной строки, считывания данных из других таблиц в целях обеспечения ссылочной целостности, записи в другие таблицы в целях генерации контрольного журнала и/или реализации функции уведомления за счет создания триггера, запускающего определяемую пользователем функцию (например, отправки сообщения электронной почты). Например, пользователь может создать триггер, который будет увеличивать на единицу количество пользователей при каждом добавлении строки в таблицу служащих EMPLOYEE.
Расширение SQL позволяет включать в один непроцедурный оператор большой объем операций по обработке данных. В качестве примеров можно привести рекурсивные запросы SQL. Использование рекурсивных запросов делает возможными, например, такие запросы:
запросы по ведомости материалов, когда пользователь желает узнать все составные компоненты какой-либо детали, все составные компоненты этих компонентов и т.д.;запросы с расчетами по выбору маршрута, когда пользователь желает определить самый выгодный с точки зрения тарифов маршрут перелета с несколькими пересадками. С помощью рекурсивного SQL может быть, к примеру, сформулирован следующий запрос: определить все возможные варианты перелета из Торонто в Хабаровск без пересадок и не более чем с тремя пересадками.
Управление контентом (DB2 Content Management): основные особенности
Контент - это содержание, информационное наполнение документа, не связанное с формой представления информации. Управление контентом - это совокупность задач поиска, доступа, хранения и интеграции всех форм деловой информации, включая аудио, видео, отсканированную графику, а также информацию, созданную программными продуктами различных разработчиков.
Важность проблемы управления контентом обусловлена лавинообразным ростом объемов накапливаемой информации (предполагается, что в период с 2004 по 2006 год в мире будет сгенерировано данных в два раза больше, чем их было накоплено за всю историю человечества), а также разнообразием форм создаваемой информации (по имеющимся оценкам 85% всей информации в мире приходится на неструктурированные данные: бумажные документы, видео- и аудиозаписи, фотографии, факсы и пр.). Поэтому если сейчас не взяться за решение проблем организации хранения, быстрого поиска, доступа и преобразования в требуемую форму, накопленные данные могут оказаться недоступными для пользователей.
Расходы на хранение информации в цифровых архивах оказываются меньше затрат на хранение физических (например, бумажных) носителей. К цифровой информации легче получить доступ и организовать в ней поиск, проще обеспечить коллективное пользование, сохранение и восстановление в случае ее разрушения.
Основной компонент IBM для управления контентом - это IBM DB2 Content Manager. Решение IBM DB2 Content Manager создано на базе продуктов WebSphere Portal и WebSphere Application Server (см. раздел 6.2), оно использует DB2 UDB в качестве сервера библиотеки метаданных.
IBM Content Manager представляет инфраструктуру управления информационным наполнением корпоративного масштаба, в которой можно хранить, извлекать и администрировать полный спектр цифровой информации, создаваемой в ходе реализации задач электронной коммерции. Можно управлять крупными архивами отсканированной графики, факсов, электронных офисных документов, файлов XML и HTML, компьютерного вывода, аудио и видео.
Интеграция информационного наполнения с приложениями, предназначенными для моделирования и реализации бизнес-процессов, обслуживания заказчиков, планирования ресурсов предприятия, управления цифровыми активами, дистанционного обучения, управления информационным наполнением Web-сайтов и других целей может облегчить и ускорить автоматизацию бизнес-процессов предприятия.
IBM Content Manager обеспечивает высокоскоростной доступ к расширенным источникам данных во всех форматах, включая видео и аудио, независимо от их местоположения. Эту технологию в IBM называют объединенным управлением данными. Программный продукт также предоставляет доступ к Lotus Notes и другим программным системам, таким как Oracle, Sybase и Microsoft SQL Server и др.
Технология объединенного управления данными отличается от решений других поставщиков, использующих, как правило, централизованное управление данными. Разработчики IBM исходят из того, что в большинстве компаний имеется несколько разных хранилищ данных, размещенных на различных аппаратно-программных платформах, находящихся в разных местах и работающих с разными типами данных. Объединенное управление данными позволяют заказчику строить систему на базе имеющейся технологической инфраструктуры, что обеспечивает более высокий уровень масштабируемости и надежности, а также позволяет снизить полную стоимость владения.
Content Manager версии 8 отличается возможностью неограниченного масштабирования по объему данных и количеству пользователей и может справиться с сотнями тысяч и более терабайт (TB) информации. В частности, цифровая библиотека CNN, содержащая 120 тыс. часов архивных материалов, которые накопились в CNN за 21 год деятельности компании, сохранена в 4-петабайтном (4096 ТB) решении по управлению информационным наполнением с возможностью дальнейшего наращивания объемов данных.
С целью снижения сложности и повышения производительности в IBM Content Manager используется технология SMART (Self Managing and Resource Tuning - самоуправление и самонастройка ресурсов).
Обычно управление видео- и аудиоданными представляет собой весьма трудоемкий процесс. Возможности для электронного поиска и извлечения соответствующих видео- и аудиофрагментов весьма скромны - ленты хранятся в библиотеке, и их совместное использование практически невозможно, поскольку доступ к ним затруднен, а находящиеся на большом расстоянии пользователи должны посылать запросы и ждать, когда им доставят нужную ленту, при этом возможности одновременной трансляции подобных данных на несколько сайтов отсутствуют. Решение DB2 Content Manager VideoCharger позволяет превратить видео- и аудиоданные в эффективный настольный инструмент, который можно использовать для обучения, продаж и взаимодействия с клиентами и партнерами. Это решение поддерживает управляемую доставку видео- и аудиоинформации с учетом особенностей среды передачи отдельным или многим клиентам, с использованием сетевой инфраструктуры компании. Видео- и аудиоданные направляются в виде потока в реальном времени, что позволяет избежать необходимости загрузки и сохранения файла перед проигрыванием материала.
Продукт IBM DB2 Content Manager OnDemand обеспечивает сохранение, просмотр и последующую доставку (в том числе по факсу) любых автоматически генерируемых компьютерных документов путем архивации счетов-фактур, ведомостей и других финансовых отчетов с помощью промышленных технологий. Благодаря интеграции с наиболее популярным программным обеспечением для поиска информации, можно быстро найти в огромных архивах необходимую для анализа и составления отчетов информацию.
Продукт IBM DB2 Content Manager CommonStore является готовым интерфейсом для интеграции информационного хранилища на базе Content Manager с корпоративными приложениями типа электронной почты (Lotus Notes или MS Exchange), системами документооборота (Lotus Domino), ERP и CRM-системами (компаний SAP и Siebel). Этот продукт обеспечивает автоматическую выгрузку неструктурированной информации из указанных приложений в архивы, что приводит к снижению системных требований к серверам приложений, улучшению их управляемости и повышению производительности.
Интерфейс CommonStore сертифицирован такими производителями ПО, как SAP, Microsoft и Siebel.
Новые функции DB2 SMART включают инструменты мониторинга производительности и оптимизатор, а также реализуют распределение рабочей нагрузки и автоматически оптимизируют запросы, так чтобы поиск по ним выполнялся быстрее.
Кратко рассмотрим ряд программных продуктов семейства DB2 Content Manager (табл. 6.2).
| 1. | Управление контентом | IBM DB2 Content Manager | инфраструктура управления контентом для хранения, извлечения и администрирования цифровых данных;интеграция всех форм информации, хранящейся в различных источниках данных;объединенное управление данными;мониторинг производительности, оптимизация запросов на основе технологии SMART (Self Managing and Resource Tuning);неограниченная масштабируемость по объемам данных и количеству пользователей;поддержка стандарта потокового видео MPEG-4, поддержка XML |
| 2. | Управление потоковой аудио- и видео- информацией | IBM DB2 Content Manage Video Charger (V.8) | передача высококачественной потоковой аудио- и видеоинформации по intranet, а также через Internet, с использованием современных стандартов, включая MPEG-4 и Apple QuickTime 5;поддержка IBM DB2 Content Management;поддержка различных скоростей передачи потокового видео, обеспечивающая низкое, среднее или высокое качество изображения;возможность определения оптимального сетевого маршрута и задания максимально возможного размера пакета (при работе в среде AIX) для повышения эффективности работы сети передачи данных;поддержка многоадресной IP-рассылки |
| 3. | Быстрый поиск, сохранение, просмотр и доставка компьютерных документов | IBM DB2 Content Manager OnDemand | сохранение, просмотр и последующая доставка (в том числе по факсу) автоматически генерируемых компьютерных документов;архивация компьютерных документов;интеграция со средствами поиска компьютерных документов |
| 4. | Интеграция документов SAP и документов других форматов в одном архиве | IBM DB2 Content Manager CommonStore for SAP | быстрый, защищенный и непрерывный доступ к данным SAP для пользователей гетерогенной сети; - поиск данных во всем наборе документов хранилища IBM Content Manager для пользователей SAP;интеграция со всеми программными модулями SAP;наличие версий для работы в средах AIX, MS Windows NT, Sun Solaris, HP-UX, IBM AS/400;возможность хранения архивов в среде OS/390 и z/OS;возможность создания копий в нескольких архивах |
| 5. | Архивация документов электронной почты Lotus Domino | IBM DB2 Content Manager CommonStore for Lotus Domino | поддержка всех платформ Lotus Domino, включая IBM AIX, AS/400, OS/2, OS/390, Linux, MS Windows NT, MP-UX, Sun Solaris;архивация сообщений электронной почты Lotus Domino, вложенных файлов и папок баз данных Lotus Domino в общем хранилище Content Manager;возможность доступа с помощью клиента Lotus Notes,Web-браузера, клиента Lotus iNotes;возможность присвоить каждому пользователю свое представление данных (за счет поддержки Content Manager);возможность сохранения документов в формате Lotus Domino;оптимизация размещения хранимых документов в памяти с целью эффективного использования дисковой памяти (старые и редко запрашиваемые данные автоматически перемещают во внешние архивы) |
Утилиты DB2 (IBM DB2 Tools)
IBM DB2 Tools - это инструменты управления данными для DB2, предназначенные для повышения производительности IBM DB2 UDB в средах z/OS и OS/390.
Инструментальные средства IBM DB2 группирует по четырем функциональным категориям: инструменты для администрирования баз данных, инструменты управления производительностью, инструменты для восстановления и репликации и инструменты для управления приложениями.
Инструменты для администрирования баз данных помогают решить наиболее общие задачи, связанные с обслуживанием и поддержкой работы баз данных. К ним относятся такие задачи, как выгрузка и повторная загрузка данных, их реорганизация, копирование и управление каталогами. Многие из этих операций влияют на производительность и перенастройку параметров и имеют важнейшее значение для соблюдения требований в отношении уровня доступности данных.
Инструменты управления производительностью играют важную роль для сохранения работоспособности среды баз данных при пиковых нагрузках. Эти инструменты позволяют пользователям отслеживать, анализировать и поддерживать быстродействие базы данных DB2, обеспечивая одновременное сокращение времени обработки транзакций и повышение уровня доступности ресурсов.
Инструменты IBM для восстановления и репликации баз данных помогают заказчикам повысить эффективность своих баз данных.
Инструменты IBM для управления приложениями баз данных позволяют создавать простые приложения для работы с отчетами, соединять их с нужными пользователю данными в определенный момент времени, проверять и изменять данные, а также контролировать операции в заданных точках.
